| A Neural Network Learns What A Face Is |
| Written by Mike James | |||
| Tuesday, 26 June 2012 | |||
|
It probably is a breakthrough in AI that we will look back on and say "this is where it really took off". A big neural network has finally done something that is close to what human brains do. After being shown lots of photos extracted from YouTube, it learned to recognize faces - without being told what a face is. Of course given that the source material is from YouTube it also learned the concept of "cat face" - and this is the amusing angle most other news reports are leading on. However, the serious aspect of this research should send shivers up your spine, so don't get too distracted laughing about cat videos. The work has been done by researchers from Stanford and Google, Quoc V. Le, Marc'Aurelio Ranzato, Rajat Monga, Matthieu Devin, Kai Chen, Greg S. Corrado, Jeff Dean, and Andrew Y. Ng, and is based on the breakthrough ideas about how neural networks should be structured invented by Geoffrey Hinton and other in 2006 but heavily elaborated since. The idea hasn't really got a single name but it is usually referred to as "deep learning" or Deep Neural Networks, DNNs. It roughly speaking corresponds to training each layer of a neural network in turn. This results in a stack of feature detectors that form a hierarchy of features from simple things like edges and blobs working up to bigger features such as faces.
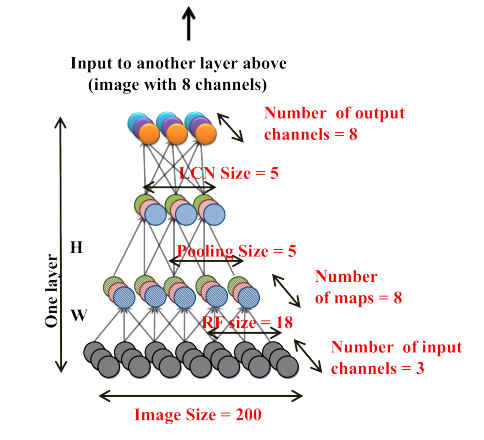
One layer of the network (in one dimension). The entire network used three repeats of this basic unit.
This news item could have been titled "neural network learns to recognize faces" but this could have been misunderstood to mean supervised training. In most cases a neural network is trained by showing it labeled examples of what it is to learn and slowly it is adjusted to give the outputs the teacher desires. This is not what happens in this case. The neural network is simply shown the images - some with faces, some without. The neural network then finds the invariants, the things which make subsets of the images the same. In this way, it eventually learns what a face is rather than being told what a face is. The important word in the last sentence is "eventually". This is a slow business and until this experiment only small networks viewing small images have been trained. They only succeeding in learning small features - edges, blobs, etc. The big question was, is this just a problem with the method or is it that we are working with too small a network? In AI the idea that the behaviour of big networks might be significantly different from small networks has long been part of the mythology. If only we could cram enough artificial neurons into a box then they would self organize even if we don't understand how. In this case it seems that some of the mythology is more or less right. The neural network in question has 1 billion connections and was trained using 200x200 images - 10 million of them. This is starting to head in the direction of the complexity of biological systems - even if there is still a long way to go. The simulation needed 1000 computers with a total of 16,000 cores to do the training. After the training it was found that the best neuron in the network achieved an 87% accuracy in detecting faces - event though no concept of "face" was input to the training. The recognition was also insensitivity to rotation, scaling and out-of-plane rotation. This means that the feature detectors really were locking on to invariants in the image.
The images that the face detector neuron gave the biggest outputs for.
A synthetic image created to maximize the stimulus to the "face neuron". This is the best representation of the feature that the network has identified.
After locating a face detection neuron the researchers went in search of other neurons that had learned other concepts. Given YouTube video stills contain a lot of human figures and cats they next showed the trained network images of the human body and cat faces. Again the network had learned to detect both types of image. There were neurons that detected human figures with an accuracy of 77% and cat faces with an accuracy of 75%.
The synthetic images that maximally stimulates the "cat face" neuron and the "human body neuron". If you squint at them your own cat and body neurons fire and you do see fuzzy representations. If you are noticing similarities in the way that the neural network had neurons that recognized high level concepts with the way that the brain is supposed to work then perhaps this is where the excitement comes into the story. This does seem to be a network architecture that has some properties of the biological analogs. As the paper concludes: In this work, we simulated high-level class-specific neu-
When comes to neural networks it seems that, as long as you get the architecture right, bigger really is better.
As stated at the start, this is a significant achievement - one that brings machine learning closer to its potential - so it's important to see beyond the cat videos and understand it as a major contribution to AI. Google seems to be serious about pushing forward with neural networks for practical ends. To quote a recent Google blog written by Andrew Ng: We’re actively working on scaling our systems to train even larger models. To give you a sense of what we mean by “larger”—while there’s no accepted way to compare artificial neural networks to biological brains, as a very rough comparison an adult human brain has around 100 trillion connections. So we still have lots of room to grow. And this isn’t just about images—we’re actively working with other groups within Google on applying this artificial neural network approach to other areas such as speech recognition and natural language modeling. Someday this could make the tools you use every day work better, faster and smarter.
More InformationBuilding high-level features using large scale unsupervised learning Related ArticlesSpeech recognition breakthrough Learn about machine learning with a demo The Paradox of Artificial Intelligence
Comments
or email your comment to: comments@i-programmer.info
To be informed about new articles on I Programmer, install the I Programmer Toolbar, subscribe to the RSS feed, follow us on, Twitter, Facebook, Google+ or Linkedin, or sign up for our weekly newsletter.

|
|||
| Last Updated ( Tuesday, 15 December 2015 ) |