| Muiti-core processors |
| Written by Administrator | ||||
| Friday, 21 May 2010 | ||||
Page 1 of 3 We are being offered ever more cores within a single processor as if this was as good as making the machine go faster. What exactly is the change from single to multi-core all about? It is often regarded as a law of nature that processors get faster with every year that passes. Some might even say that we rely on it to make each generation of ever-more-inefficient software usable! 
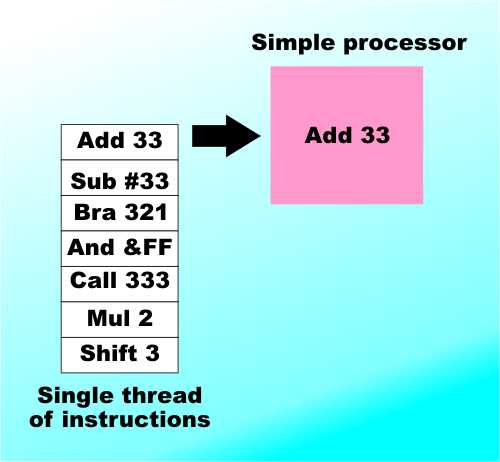
Of course it isn’t a law of nature at all, as hardware engineers have to work at it and think up new and clever ways of making it all happen. Now it seems the classical design that has provided the ever increasing processor power has run out of steam. The new way isn’t to increase the clock speed or to increase the sophistication of the design but to simply use more than one processor within a single chip. Currently two-core processors are common, with quad-core, hex-core and even twelve-core processors following close behind. Given that many motherboard designs also include mulitple processors, typically four, the standard desktop machine could soon have 48 processors waiting to do something. Is this a step in the right direction? This idea is simple and deceptively attractive and the answer has to be yes? Surely two processors are better than one? The real answer isn’t quite so simple. Multi-core isn't a sudden new trend, it is simply an enevitable next step in increasing how much a processor does on each tick of the system clock. Single-coreThe simplest design for a processor is based on it getting a single instruction from memory, obeying it, storing the results back in memory and then moving on to the next instruction. The only way of speeding up this “one-at-a-time” approach is to increase the clock speed – i.e the rate at which each step is taken. The number of clock cycles needed to carry out an instruction varies according to the complexity of the instruction, how many items have to be fetched from memory and what has to be done with them, but in general the faster the clock the more instructions completed per second.
A simple processor reads and obeys a single instruction at a time
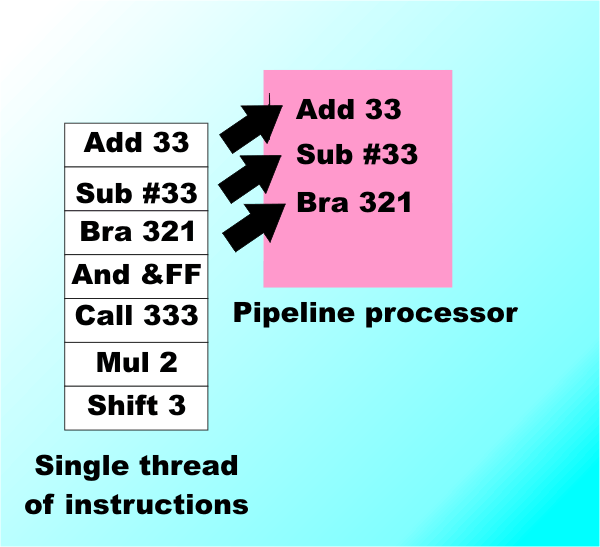
This is how all of the first and second generation of processors worked – the 8086, 386 and 486. Until quite recently increasing the clock speed was the headline news in claiming a faster processor. So much so that the processor clock often ran faster than the other clocks in the system. The 486 was the first processor to implement clock doubling and effectively separate the system clock from the processor clock. For example, some of Intel’s fastest processors run at 3.4GHz but the rest of the system runs at 800MHz – the speed of the Front Side Bus which connects the processor to the main memory. You might think that running the main memory slower than the processor would be the cause of a big slowdown and you would be correct if it wasn’t for the use of cache. Essentially the data that the processor needs to access is transferred to high speed cache memory the first time it is needed and is available for reuse thereafter. The idea is that the processor runs at full speed while it is working with the cache but everything does slow down when it needs to work with main memory. The problem of keeping the processor doing something useful increases with the gap between the processor clock and the system clock. Pipelines – instruction parallelSlowly but surely the number of transistors that could be built on a typical chips has been increasing. The problem is what to do with them to make the processor go faster? At first it was easy to add additional functional units to do arithmetic faster and to add additional internal storage – registers - but at about the time of the Intel 486 processors had everything they could use to run a program in the one-instruction at a time way. The next step was to use a clever way to increase the number of instructions that were obeyed per clock cycle. The only way to do this was to turn the process into a “production line” for obeying instructions. Instead of fetching an instruction from memory on one clock pulse, decoding it on the next, starting to obey it on the next, and so on, the new processors were built as processing pipelines fetching and decoding new instructions before the current one has been completely finished with. Instructions move through the pipeline edging their way to completion with each clock pulse. A modern Pentium family processor has between 10 and 20 pipeline stages depending on its exact type. This sort of processor is also called “superscalar” or instruction parallel because more than one instruction is being processed at any one time.
A pipeline processor attempts to deal with more than one instruction at a time, moving each one through stages like an assembly line.
<ASIN:0123705916> <ASIN:032143482X> |
||||
| Last Updated ( Thursday, 20 May 2010 ) |