| Improve SQL Performance – Know Your Statistics |
| Written by Ian Stirk |
| Monday, 02 April 2012 |
|
Data statistics can have a huge impact on both whether an index is used, and also how it is used. In this article we examine these statistics, in particular identifying if they are up to date, since stale statistics can result in queries taking much longer to run.
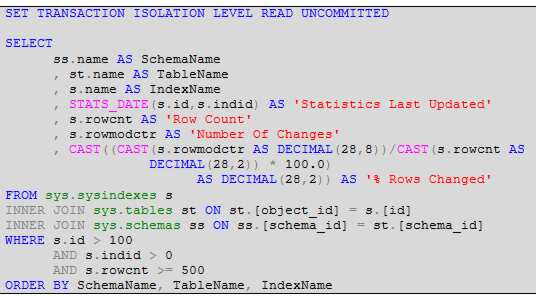
In A Generic SQL Performance Test Harness I showed how SQL Server’s Dynamic Management Views (DMVs) can be used to identify and measure the performance of individual SQL Queries. The harness allows you to make changes, for example adding an index, and measure any subsequent improvement. In that article I said data statistics can have a huge impact on both whether an index is used, and also how it is used. In this article I will examine these statistics, in particular identifying if they are up to date, since stale statistics can result in queries taking much longer to run. As an example of how stale statistics can affect query performance, I have known cases where queries have taken many hours to complete, but run in a seconds after the relevant statistics have been updated. Typically an index is created to improve the performance of your queries. However, whether or not an index is used depends on many factors, including the statistics associated with the index’s column data. Statistics describe the distribution and density of column values. Using the values supplied in a query’s WHERE clause, the SQL Server query optimizer is able to use the statistics for a given index to estimate the number of rows that would be returned. The optimizer can then decide whether or not to use an index, and if it does use the index, how it is used (i.e. seek, scan, or lookup). As you can see, statistics are a very important part of performance. To get better performance, it is important to ensure the statistics are up to date. The state of your statisticsTypically, if a table contains more than 500 rows, more than 20% of the rows need to change (inserted or altered) before the statistics of the underlying indexes are automatically updated. If a table that has 1,000,000 rows, it will need to have 200,000 changes before the statistics are automatically updated. If such a table has 10,000 updates each day, it would take 20 days (200,000 divided by 10,000) before the statistics are automatically updated to reflect the changing data, until that time the statistics become increasingly out of date. For some queries, stale statistics can mean the query runs very slowly (hours instead of seconds). In this case, it makes sense to update these statistics yourself rather than wait for SQL Server to automatically update them. This will provide the queries with the latest information about the density and distribution of data values, thus allowing the optimizer to produce a better execution plan and obtain the data more efficiently. Typically the UPDATE STATISTICS command is used, with a table name supplied as a parameter, to update the statistics. However, this causes all the indexes associated with the table name to have their statistics updated, whether they need to be updated or not. I think this is inefficient, a better approach would be to update only those statistics whose indexes have changed, and this is possible by additionally specifying the name of the index as a parameter to the UPDATE STATISTICS command. We can determine which indexes need to have their statistics updated by looking at the current state of the statistics. To view the current state of the statistics associated with your indexes, you should run the following SQL query on the relevant database:
(click to enlarge)
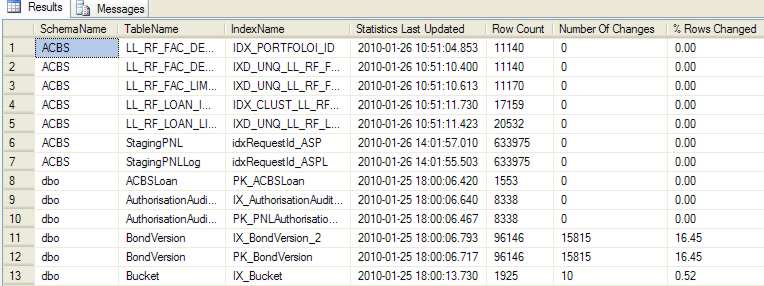
The script starts with the statement: SET TRANSACTION ISOLATION LEVEL The purpose of this is to ensure the SQL that follows does not take out any locks and does not honour any locks, allowing it to run faster and without hindrance. The script outputs for each qualifying index, its schema, underlying table, index name, when its statistics were last updated, the number of rows in the index, the number of rows changed since the statistics were last taken, and the percentage of rows changed. The script filters out indexes with an index id (indid) of 0 because these aren't indexes, they're heaps. It also filters out indexes with fewer than 500 rows, because statistics are more important for larger tables. Additionally, it also filters out system objects. The results are sorted by schema name, table name, and index name. Here is an example of the type of output produced by this script:
(click to enlarge) Now we know the individual indexes that have changed, and that should benefit from having their statistics updated, the next step would be to update the statistics of these changed indexes. This can be done manually, but ideally we should try to automate this, and we will, but that's another article... ConclusionDMVs provide a quick and easy way to investigate performance problems, including identifying indexes which should have their statistics updated. There really are a great number of SQL Server secrets that DMVs can reveal. For further information, see my recent book SQL Server DMVs in Action which contains more than 100 useful scripts.
Related articles:Identifying your slowest SQL queries Improve SQL performance – find your missing indexes A Generic SQL Performance Test Harness SQL Server DMVs in Action (Book Review)
Comments
or email your comment to: comments@i-programmer.info
To be informed about new articles on I Programmer, subscribe to the RSS feed, follow us on Google+, Twitter, Linkedin or Facebook or sign up for our weekly newsletter. |
| Last Updated ( Monday, 02 April 2012 ) |