| The PaSh Project - Advancing the Unix Philosophy One Step Further |
| Written by Nikos Vaggalis | |||
| Thursday, 04 November 2021 | |||
|
The PaSh Project gives your POSIX script superpowers by utilizing parallelization in order to speed up execution times. This leads to faster results for data scientists, engineers, biologists, economists, administrators, and programmers. I remember the time when the saying was "Learn Perl so you don't have to learn the Shell and its hundreds of utilities". This also serves as a lesson to those who are quick to denounce technologies as 'dead'. There's a time where a new use case revitalizes an old technology. So what is meant by "Unix philosophy"? It's taking simple, high quality, components and combining them together in smart ways to obtain a complex result. An example which encapsulates this notion comes straight from the PaSh documentation and shows how you can use many utilities and pipes and redirections to combine and filter them, to get at the desired outcome: Consider the following spell-checking script, applied to two large markdown files f1.md and f2.md
The speed of an operation like this would depend on the size of the two files. It could take seconds to minutes. What if you could speed it up by breaking it up into pieces that would run in parallel, and afterwards combine their results? You can. PaSh is such a system for parallelizing POSIX shell scripts, shown to achieve order-of-magnitude performance improvements. Given a shell script, PaSh converts it to a dataflow graph, performs a series of semantics - preserving program transformations that expose parallelism, and then converts the dataflow graph back into a POSIX script. The new parallel script has POSIX constructs added to explicitly guide parallelism, coupled with PaSh-provided Unix-aware runtime primitives for addressing performance- and correctness-related issues. For instance the script above run from Pash with -w 2, that is 2x-parallelism, would create 2 pipes which it would then run in parallel. Therefore, the dataflow graph would look like:
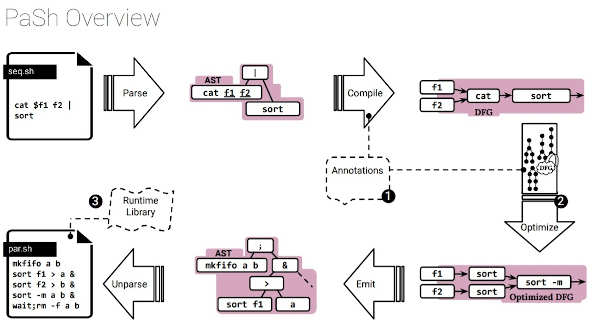
You could say that, there's GNU Parallel for that too. The problem with Parallel is that it doesn't know the semantics of commands like grep, so it is hard to use. The user has to write a carefully parameterized command for these tools to parallelize a task while also some commands have ad-hoc custom parallel flags like -j, --jobs, --parallel. These are all different, hard to use, and hard to compose. PaSh instead has a compiler which works in the following way:
Since PaSh is a source-to-source compiler, it allows the optimized shell script to be inspected and executed using the same tools, in the same environment, and with the same data as the original script. The other two main components of PaSh are annotations, a lightweight annotation language which allows command developers to express key parallelizability properties about their commands and a small runtime library providing the PaSh compiler with high-performance primitives and supporting its key functions.
Various benchmarks on common Unix one-liners show a magnitude of 60 in performance enhancement. PaSh can be run on Ubuntu, Fedora, Debian, and Arch. Use one of the following ways to set it up:
And on Windows WSL too. More InformationPaSh: Light-touch Data-Parallel Shell Processing Related ArticlesThree Tips for the Linux Shell Addict To be informed about new articles on I Programmer, sign up for our weekly newsletter, subscribe to the RSS feed and follow us on Twitter, Facebook or Linkedin. 
Comments
or email your comment to: comments@i-programmer.info |
|||
| Last Updated ( Thursday, 04 November 2021 ) |