
| A Lightning Fast JSON Parser Library |
| Written by Nikos Vaggalis | |||
| Thursday, 14 October 2021 | |||
|
simdjson is a C++ library that can parse JSON documents very fast. Version 1. 0 has been just released. How does it compare? Does parsing 3 gigabytes of JSON per second sound fast enough? This efficiency is mainly achieved due to the library under the hood using SIMD instructions, which excel at data level parallelism by fitting operations many times over per instruction, even under a single core.
Parsing fast is not only applicable to huge dumps of JSON, which the related benchmarks are applied upon. The same speed increase is experienced when parsing millions of small JSON documents per second. That aside, it can also minify JSON files by stripping spaces, tabs, newlines, and carriage returns therefore saving great amounts of space. Version 1. 0 offers a new, "On Demand", frontend in addition to the standard DOM-based one, which is flagged as the default from now on. What's the difference, you ask? In the DOM-based approach, the document is parsed entirely and materialized in an in-memory construction. The On Demand approach feels like a DOM approach, but it sidesteps the construction of the DOM tree. It is entirely lazy: it decodes only the parts of the document that you access. And what is the actual advantage in that? With On Demand, if you open a file containing 1000 numbers and you need just one of these numbers, only one number is parsed. If you need to put the numbers into your own data structure, they are materialized there directly, without being first written to a temporary tree. Thus we expect that the simdjson On Demand might often provide superior performance, when you do not need to materialize a DOM tree Other than that, release 1. 0. 0 adds several other key features:
As a simple example this is how you use the library to parse under the DOM based frontend:
Therefore, no matter what language you are writing code in, you can still leverage simdjson's advantages. More Informationsimdjson: Parsing gigabytes of JSON per second Related ArticlesGoogle JavaScript Engine Speeds JSON Parsing Emacs 27.1 Adds Native JSON Parsing
To be informed about new articles on I Programmer, sign up for our weekly newsletter, subscribe to the RSS feed and follow us on Twitter, Facebook or Linkedin. 
Comments
or email your comment to: comments@i-programmer.info |
|||
| Last Updated ( Saturday, 16 October 2021 ) |
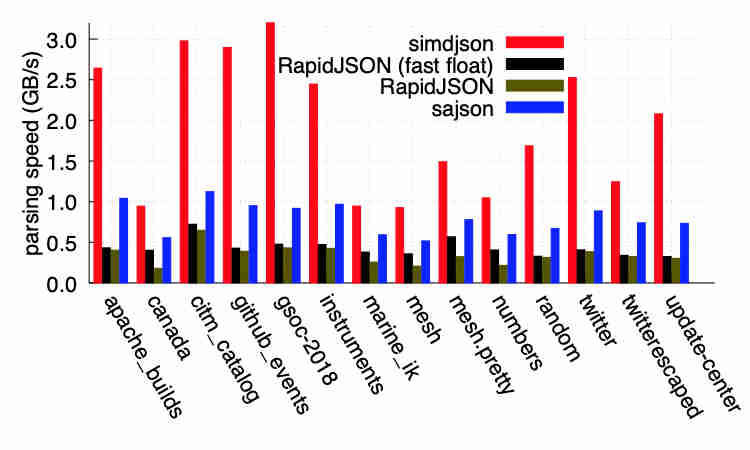
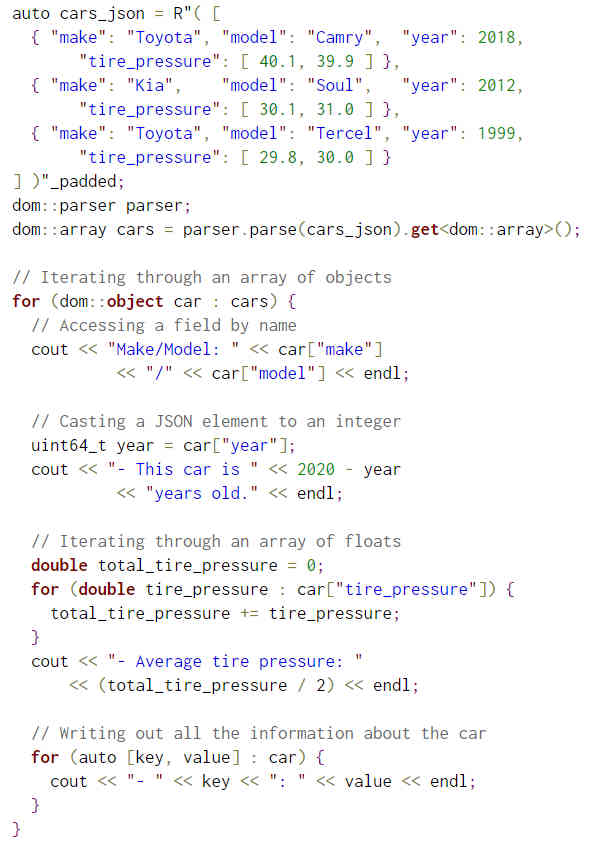 You might think that since it is a C++ lib that only devs writing in C++ are benefited. This is not true as there's already bindings for other languages like Go, Ruby, Python and more, while there's even a port for PostgreSQL too in
You might think that since it is a C++ lib that only devs writing in C++ are benefited. This is not true as there's already bindings for other languages like Go, Ruby, Python and more, while there's even a port for PostgreSQL too in 