| SQL Server 2019 Includes Hadoop And Spark |
| Written by Kay Ewbank | |||
| Thursday, 04 October 2018 | |||
|
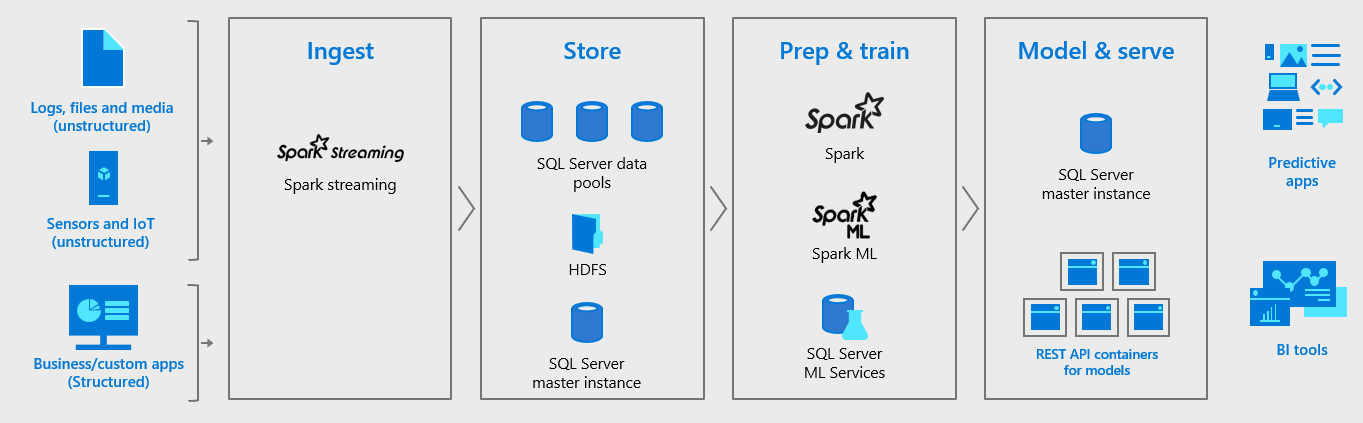
SQL Server 2019 will have Apache Spark and Hadoop Distributed File System packaged with its own engine to provide a unified data platform and to make the database more fitting for analysis of massive datasets. The preview of SQL Server 2019 was shown at Microsoft Ignite. Writing about the new version in a blog post, Asad Khan, Principal PM Manager, SQL Server, said: "For 25 years, SQL Server has helped enterprises manage all facets of their relational data." which rather airbrushes out the fact SQL Server started life as Sybase SQL Server in 1987. In terms of what's new, the most interesting change is the introduction of big data clusters that packages Apache Spark and Hadoop in with SQL Server. This means you can use Spark with SQL Server over both relational and non-relation data sitting in SQL Server, HDFS and other systems. The new feature is built on top of the Kubernetes container platform, and the developers say the use of Kubernetes means a single server cluster can be deployed using a single command and you'll have a cluster available to use in around 30 minutes. You can also run advanced analytics and machine learning with Spark, use Spark streaming to data to SQL data pools, and use Azure Data Studio to run Query books that provide a notebook experience.
Azure Data Studio is what was called SQL Operations Studio when in preview. It's described as a lightweight, modern, open source, cross-platform desktop tool for the most common tasks in data development and administration. It can be used to connect to SQL Server on premises and in the cloud, and has tools for editing and running queries; visualizing data with built-in charting of your result sets; creating custom dashboards; and analyzing data in integrated notebooks built on Jupyter. Data in the clusters can also be monitored using a pipeline of tools to collect monitoring data, including Telegraf, Grafana and InfluxDB, as well as SQL Server and Spark. Microsoft intends the SQL Server 2019 Big Data clusters to provide a complete AI platform, where data is ingested via Spark Streaming or traditional SQL inserts and stored in HDFS, relational tables, graph, or JSON/XML. Once within the cluster, the data can be worked on using either Spark jobs or Transact-SQL queries. It can then be run through machine learning model training routines in Spark, or via programming languages including Java, Python, R, and Scala. This route uses SQL Server Machine Learning Services in the master instance to run R, Python, or Java model training scripts. Whether Spark or the more conventional language route is chosen, it is possible to use open-source machine learning libraries, such as TensorFlow or Caffe, to train models. The resulting models can then be used via batch scoring jobs in Spark, from T-SQL stored procedures for real-time scoring, or encapsulated in REST API containers hosted in the big data cluster. A second set of changes designed to make SQL Server more generally useful is a revamp of PolyBase (which can be used to query data from external sources using T-SQL) so that in addition to Hadoop and Azure Blob storage, both of which were already supported, you can now query data from Oracle, Teradata and MongoDB. There's no doubting Microsoft's desire to keep SQL Server relevant no matter where data is stored; it'll be interesting to see whether the plans work.
More InformationRelated ArticlesSQL Server 2017 GA For Linux And Windows Microsoft R Server 9.1 Adds ML Enhancements SQL Server vNext Improves SSAS
To be informed about new articles on I Programmer, sign up for our weekly newsletter, subscribe to the RSS feed and follow us on Twitter, Facebook or Linkedin. 
Comments
or email your comment to: comments@i-programmer.info |
|||
| Last Updated ( Monday, 04 March 2019 ) |