| Apache Gobblin Reaches Top Level Status |
| Written by Kay Ewbank | |||
| Tuesday, 23 February 2021 | |||
|
Apache has announced that Gobblin, an open-source distributed data integration framework for making big data integration simpler, has reached top-level project status. Apache Gobblin is a distributed data integration framework that simplifies common aspects of big data integration such as data ingestion, replication, organization and lifecycle management for both streaming and batch data ecosystems.
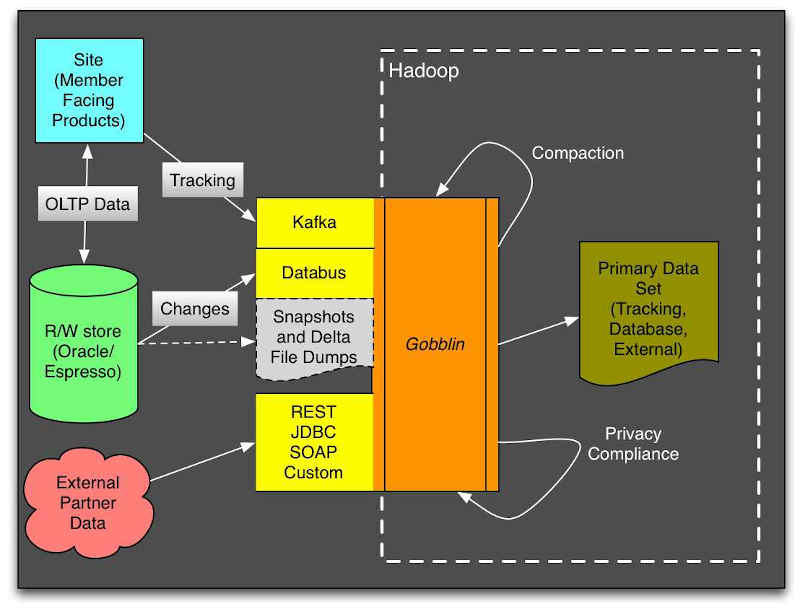
Gobblin was developed by LinkedIn for data integration. LinkedIn has hundreds of terabytes of internal and external data a day, including time-sensitive Kafka events emitted when members take certain actions like viewing a page, making a post, or commenting on someone else’s post.
Gobblin is used to bring external and internal datasets together into one central data repository for analytics (HDFS). LinkedIn made Gobblin open source in 2015, and it entered the Apache Incubator in February 2017. In that time LinkedIn has continued development, and the project has now entered Apache top level status. Gobblin can be used to ingest and export data from a variety of sources and sinks into and out of the data lake. It is optimized and designed for ELT patterns with inline transformations on ingest. Gobblin also organizes the data within the lake through compaction, partitioning, and deduplication, and carries out lifecycle management in terms of data retention. It can also be used for tasks including fine-grain data deletions. In addition to LinkedIn, Gobblin already runs in production at petabyte-scale at companies including PayPal and Verizon, and is available as a service supporting programmatic triggering and orchestration of data plane operations. In addition to the announcement of top level status, LinkedIn has announced a new evolution of Gobblin called “FastIngest,” that improves ingestion speed and efficiency, as well as query performance. As part of the update, LinkedIn has developed a new streaming-based Gobblin Pipeline that reduces ingestion latency from 45 minutes to only 5 minutes.
More InformationRelated ArticlesLinkedIn Open Sources Data Streaming Tool Apache Kafka 2.7 Updates Broker Kafka 2.5 Adds New Metrics And Improves Security Hadoop 3 Adds HDFS Erasure Coding
To be informed about new articles on I Programmer, sign up for our weekly newsletter, subscribe to the RSS feed and follow us on Twitter, Facebook or Linkedin. 
Comments
or email your comment to: comments@i-programmer.info |