| Unicode Version 14 Announced |
| Written by Nikos Vaggalis | |||
| Friday, 24 September 2021 | |||
|
The venerable Unicode standard gets an update. We report the news and go behind the scenes with a brief look at the standard's philosophy and practical use. Most people stop thinking about Unicode at the introduction of new Emoji characters. However, the main purpose of the Unicode standard isn't just sharing expressive characters to be used on mobile apps just for fun; it also facilitates communication in every humanly readable language as well as supporting science and research with its scientific symbols and ancient language scripts.
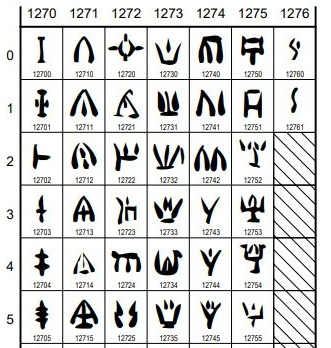
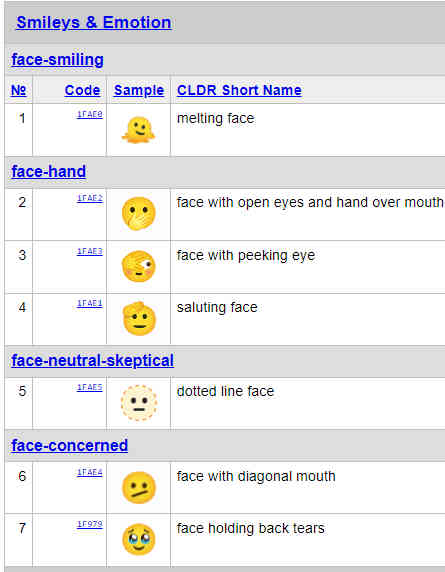
In the Unicode consortium's own words: The Unicode Standard is the foundation for all modern software and communications around the world, including all modern operating systems, browsers, laptops, and smart phones-plus the Internet and Web (URLs, HTML, XML, CSS, JSON, etc. ). With that said Unicode v14 has added 838 characters, including five new scripts and 37 new emoji characters. The scripts are:
This goes to show that Unicode is not just useful for communication in the modern world, but is also the Gatekeeper that safeguards the memory of niche or extinct cultures. Elaborating more, technically a Unicode Script (according to Wikipedia) is: A collection of letters and other written signs used to represent textual information in one or more writing systems. Some scripts support one and only one writing system and language, for example, Armenian. Other scripts support many different writing systems; for example, the Latin script supports English, French, German, Italian, Vietnamese, Latin itself, and several other languages. In regular expressions, you'll find them usually notated with \p{..} , like \p{Latin} etc. As far as the fun aspect goes, v14 also added the following 37 emoji characters:
At I Programmer we have extensive coverage of the Emoji world. Check Emoji SubCommittee ReOpens Submissions Process and World Emoji Day Chooses Syringe To Sum Up 2021 for the latest.
Some other minor additions found their way in, including:
All fine, but in order to get your hands on the new characters, you'll have to wait until your favorite apps and fonts get upgraded to support the new standard. The same delay applies to programming language support. Perl is always the fastest to adopt the newest Unicode standards. For instance Unicode 10 support came with Perl version 5.28 back in 2018, while Perl 5.32.0 came with Unicode 13. The latest version of Perl is 5.34.0, released in May 2021, and as such it has not incorporated the latest standard but I guess that the next one will. And what can you do with Scripts programming-wise? Use them in manipulating text such as in regular expressions. This is described in Advanced Perl Regular Expressions - Extended Constructs where I have a file: myimageऄwithधDevanagariमcharsफ'.png in which Hindi DEVANAGARI characters are intermixed with Latin. The file needs to be distributed to multiple platforms and operating systems that might not be Unicode compatible. Thus its file name needs to be portable and compatible with the file systems of the various operating systems. What is the best way to achieve this? By renaming the file to contain characters only from the universally recognizable ASCII character set, which means we have to strip it out of all the non-ASCII characters. But to do that, we have to first introduce Blocks in addition to Scripts. According to perlunicode: Unicode also defines blocks of characters. The difference between scripts and blocks is that the concept of scripts is closer to natural languages, while the concept of blocks is more of an artificial grouping based on groups of Unicode characters with consecutive ordinal values. For example, the "Basic Latin" block is all the characters whose ordinals are between 0 and 127, inclusive; in other words, the ASCII characters. The "Latin" script contains some letters from this as well as several other blocks, like "Latin-1 Supplement", "Latin Extended-A", etc., but it does not contain all the characters from those blocks. Armed with this knowledge we can proceed in solving the portability issue. There is the [[:ascii:]] POSIX class and/or the Unicode \p{InBasicLatin} block that do match all ASCII characters, thus by negation [^[:ascii:]] or P{InBasic_Latin} we get to all non-ASCII ones. As everything in Perl, TMTOWTDI (there's more than one way to do it). and this example can be the basis for forming more elaborate use cases later on. But what do we actually mean by ASCII? We mean characters with ordinal values below 128 (in other words US English only), thus we need to remove those beyond 127 which leads us to a 'remove all characters whose ordinal value is > 127' condition for use in constructing the regex. For the solution check the rest of the article, but the point is that the Unicode standard organizes concepts into concrete blocks so that you can work with them intuitively. All the information about Scripts, Blocks and the rest can be found in the crisp documentation of the standard up on Unicode.org. And you can find all the new Emoji additions at Emoji recently added. More InformationAnnouncing The Unicode® Standard, Version 14.0 Related ArticlesAdvanced Perl Regular Expressions - Extended Constructs Advanced Perl Regular Expressions - The Pattern Code Expression Query Unicode From The Command Line Automatically Generating Regular Expressions with Genetic Programming
To be informed about new articles on I Programmer, sign up for our weekly newsletter, subscribe to the RSS feed and follow us on Twitter, Facebook or Linkedin. 
Comments
or email your comment to: comments@i-programmer.info |
|||
| Last Updated ( Friday, 24 September 2021 ) |