| Hadoop Submarine Adds Deep Learning To Hadoop |
| Written by Kay Ewbank | |||
| Wednesday, 26 December 2018 | |||
|
There's a new Hadoop project for building deep learning frameworks, like TensorFlow, on Apache Hadoop. Submarine has integrations with Zeppelin and Azkaban for running jobs. Deep Learning skills are increasingly a marketable commodity and this Deep Learning course is a good starting point. Hadoop is a framework that can be used to process large data sets across clusters of computers using simple programming models. The new project aims to improve the support for using deep learning to analyze Hadoop data. For greater understanding of its potential check out this Big Data Hadoop Training.
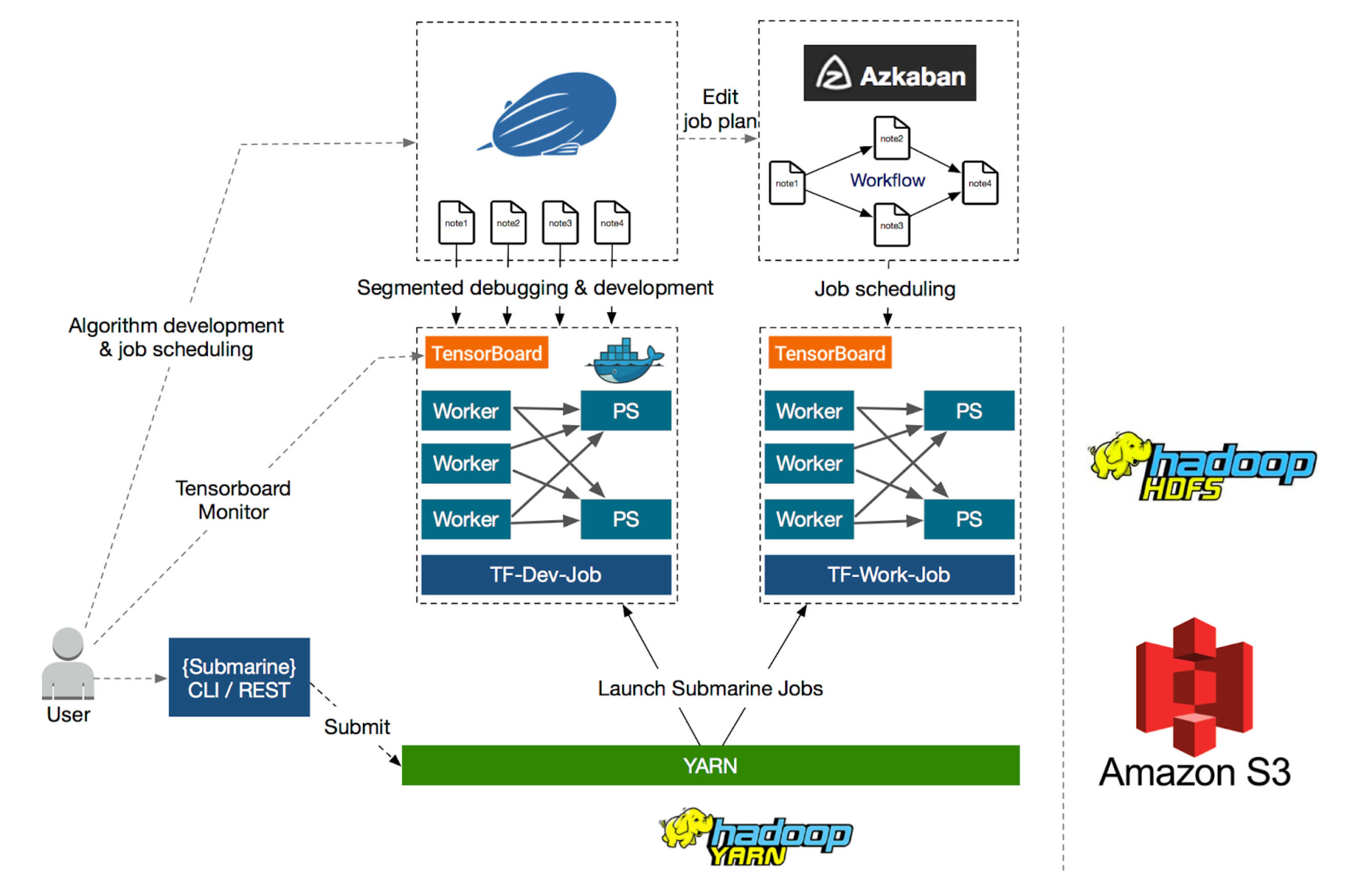
The aim of Hadoop Submarine is to make it easier to launch, manage and monitor distributed deep learning/machine learning applications created in frameworks such as TensorFlow. Other improvements alongside Submarine include better GPU support, Docker container support, container-DNS support, and scheduling improvements. The developers say the improvements make it as easy to run distributed deep learning/machine learning applications on Apache Hadoop YARN as it would be to run such applications locally. Users will be able to run deep learning workloads with other ETL/streaming jobs running on the same cluster. The Submarine project has two parts: the Submarine computation engine and a set of submarine ecosystem integration plugins and tools.
The computation engine submits customized deep learning applications (like Tensorflow, Pytorch, etc.) to YARN from the command line. These applications run side by side with other applications on YARN, such as Apache Spark and Hadoop Map/Reduce. A set of integrations sit on top of the computation engine. The current list adds integration between Submarine and Zeppelin, and between Submarine and Azkaban. The Zeppelin integration means data scientists can code inside Zeppelin notebooks, and submit/ and manage training jobs directly from the notebook. Zeppelin is a web-based notebook that supports interactive data analysis via SQL, Scala, and Python. to make data-driven, interactive, collaborative documents. There are more than 20 interpreters in Zeppelin, covering products such as Spark, Hive, Cassandra, Elasticsearch, Kylin, and HBase for collecting data, cleaning data, feature extraction etc. These can be used first, then the machine learning model training can work on clean data. Azkaban is a batch workflow scheduling service. It was developed at LinkedIn to run Hadoop jobs. Azkaban resolves the ordering through job dependencies and provides an easy to use web user interface to maintain and track workflows. The Integration with Submarine means a data scientist can submit a set of tasks with dependencies directly to Azkaban from notebooks. The developers say that the overall goal of the Hadoop Submarine project is to provide the service support capabilities of deep learning algorithms for data (data acquisition, data processing, data cleaning), algorithms (interactive, visual programming and tuning), resource scheduling, algorithm model publishing, and job scheduling. The use of Zeppelin takes care of the data and algorithm, while adding in Azkaban handles the job scheduling. The plan is that the three-piece toolset: of Zeppelin, Hadoop Submarine and Azkaban will provide an open and ready-to-use deep learning development platform.
More InformationRelated ArticlesHortonworks Plans To Take Hadoop Cloud Native Hadoop 3 Adds HDFS Erasure Coding Hadoop 2.9 Adds Resource Estimator Hadoop SQL Query Engine Launched
To be informed about new articles on I Programmer, sign up for our weekly newsletter, subscribe to the RSS feed and follow us on Twitter, Facebook or Linkedin. 
Comments
or email your comment to: comments@i-programmer.info |
|||
| Last Updated ( Thursday, 10 January 2019 ) |