| Twitter Indexes Every Single Tweet Ever |
| Written by Kay Ewbank | |||
| Thursday, 27 November 2014 | |||
|
Twitter is creating an index of every public tweet ever made, to make it possible to search without restrictions on the age of the tweet. This is being achieved using Apache Mesos, an open source cluster manager that provides efficient resource isolation and sharing across distributed applications, or frameworks. Until now, the search results were limited to tweets from roughly the last week because the search engine relied on looking through the tweets stored in server RAM. Twitter has now announced, in a post from Yi Zhuang on its Engineering blog, that work has now been completed on indexing all tweets since 2006, with work planned for earlier tweets to be added. The search service indexes half a trillion documents and serves queries with an average latency of under 100ms.
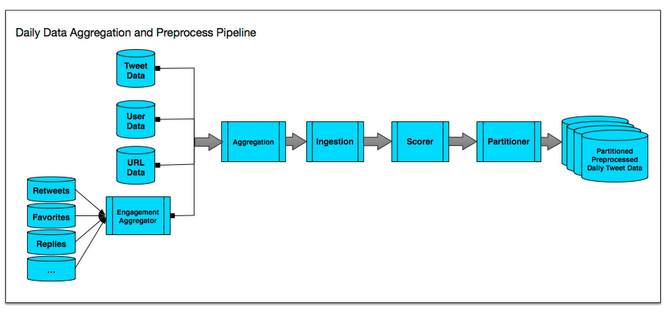
Source code and tests have been shared between the existing one-week index and the new index where possible. The scalability figures are enough to give data managers nightmares. The full index is more than 100 times larger than the real-time index and grows by several billion Tweets a week. The developers say that partitioning is unavoidable at this scale, but the interface hides the underlying partitions so that internal clients can treat the cluster as a single endpoint. The system consists of four main parts: a batched data aggregation and preprocess pipeline; an inverted index builder; Earlybird shards; and Earlybird roots. The ingestion pipeline for Twitter’s real-time index processes individual Tweets one at a time, but the full index uses a batch processing pipeline, where each batch is a day of Tweets. In order to re-use code, the developers packaged the relevant sections of the real-time code into Pig User-Defined Functions so that it could be reused in Pig jobs. The team also created a pipeline of Hadoop jobs to aggregate data and preprocess Tweets on Hadoop. The pipeline is run against a single specific day of Tweets, which means it can be massively parallelizable on Hadoop.
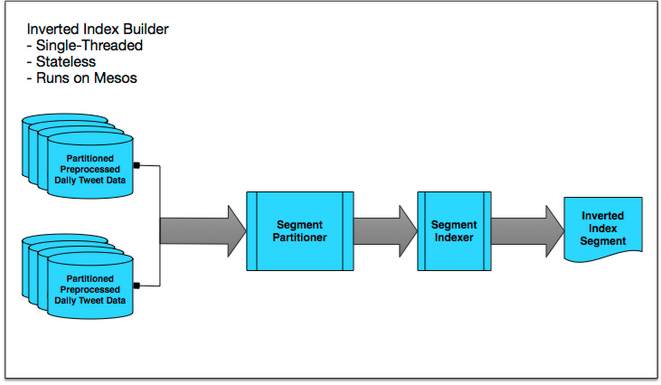
The inverted index is created by taking the daily data aggregation output of one record per tweet, and running it through single-threaded, stateless inverted index builders that run on Mesos. The inverted index builder consists of a segment partitioner that groups multiple batches of preprocessed daily Tweet data from the same partition into bundles, and a segment indexer that inverts each Tweet in a segment, builds an inverted index and stores the inverted index into HDFS.
The inverted index builders are single-threaded, stateless, and are massively parallelized on Mesos – the developers say they’ve launched well over a thousand parallel builders in some cases. The team has rebuilt inverted indices for nearly half a trillion Tweets in only about two days, and their bottleneck is actually the Hadoop namenode – not many jobs can claim that! The inverted index builders produced hundreds of inverted index segments which were then distributed. Sharding had to be introduced as each machine could only serve a small portion of the full Tweet corpus. Because the index clusters needed to grow continuously, the sharding could not be controlled using simple hash partitioning. Instead, the team created a two-dimensional sharding scheme to distribute index segments onto the servers. The historical tweets are divided into time tiers; data is divided within these into partitions based on a hash function; the hash partitions are then divided into chunks called Segments, and these are grouped together based on how many could fit on each machine. The servers are then replicated to increase serving capacity and resilience. The two-tier sharding means Twitter can increase the data capacity by adding time tiers, leaving existing time tiers unchanged. As RAM would be too expensive for storage, the team is using SSDs, but these are orders of magnitude slower than RAM, so some of the most interesting work has been in areas such as tuning kernel parameters to optimize SSD performance, packing multiple DocValues fields together to reduce SSD random access, loading frequently accessed fields directly in-process and more. However, the details of these optimizations have not so far been made public. The end result of all the work is that complete results from the full index will appear in the “All” tab of search results on the Twitter web client, and for Twitter for iOS and Twitter for Android apps. Over time, you’ll see more Tweets from this index appearing in the “Top” tab of search results and in new product experiences powered by this index. The blog post says that there is still more exciting work ahead, such as optimizations for smart caching. If this project sounds interesting to you, Twitter could use your help.
More InformationBuilding a complete Tweet index Related ArticlesWhy You Shouldn't Collect Data - What The Government Could Do With Location Data Twitter Used To Map Happiness In New York To be informed about new articles on I Programmer, install the I Programmer Toolbar, subscribe to the RSS feed, follow us on, Twitter, Facebook, Google+ or Linkedin, or sign up for our weekly newsletter. 
Comments
or email your comment to: comments@i-programmer.info |
|||
| Last Updated ( Wednesday, 28 January 2015 ) |