| No Winners In First Winograd Schema Contest |
| Written by Sue Gee | |||
| Wednesday, 03 August 2016 | |||
|
Results of the first ever Winograd Schema Challenge were unveiled recently at the International Joint Conference on Artificial Intelligence (IJCAI-2016). The low scores reflect how far there is to go before machines understand human language and commonsense reasoning.
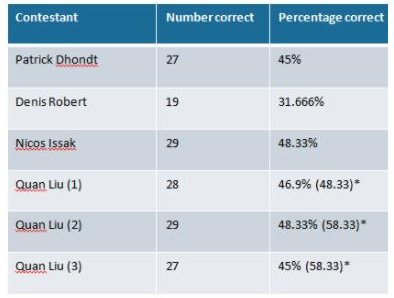
As we reported when it was announced in 2014, see A Better Turing Test - Winograd Schemas this new competition was designed to judge whether a computer program has truly modeled human level intelligence. It is seen as an alternative to the Turing Test which has tended to become discredited due to the ploys used by chatbots to avoid answering questions, the latest of which could be to stay silent by pleading the 5th Amendment, see A Flaw In Turing's Test? The vehicle proposed by Hector Levesque, Professor of Computer Science for the contest, Winograd Schema questions, requires participants to provide answers to questions which are ambiguous when you simply parse the construction of a sentence and only possible to answer by having the sort of knowledge that humans consider common sense, as demonstrated with this example: The trophy would not fit in the brown suitcase because it was too big. What was too big? In the statement "it" could refer either to the trophy or to the suitcase. The "right" answer is immediately obvious to a human who will draw on knowledge about the relatives sizes of suitcases and trophies and it is probably not subtle enough to fool a computer which could be briefed with information about fitting objects into containers. But other Winograd Schemas are more subtle and give humans pause for thought: The town councillors refused to give the angry demonstrators a permit because they feared violence. Who feared violence? In fact, in testing Winograd Schemas constructed in preparation for the contest, one was consistently given the "wrong" answer by all the human subjects, although overall the 21 participants agreed with the intended answers for the materials 91% of the time. Two types of material have been prepared for the competition, with the Winograd Schemas being reserved for the second round, to be used in the event that competitors have reached a threshold of at least 90% on the first round. The first round relies on a slightly less tricky questions, Pronoun Disambiguation Problems (PDPs) which require commonsense reasoning to understand the relationships between object and events. PDPs are abundant in everyday language and for the contest were collected from children’s literature, with this being one example: Babar wonders how he can get new clothing. Luckily, a very rich old man who has always been fond of little elephants understands right away that heis longing for a fine suit. As he likes to make people happy, he gives him his wallet. Qesstion: Who is "he" in “he is longing for a fine suit”: As explained by Charles Ortiz, Director of Artificial Intelligence at Nuance Communications which sponsors the contest: "While simple for humans, AI computer systems today lack sufficient commonsense knowledge and reasoning to solve these questions. Each Schema and PDP involves a variety of different types of relationships, such as cause-and-effect, spatial, temporal and social relationships." In preparatory tests of 108 PDP problems, which were conducted with 19 human subjects, 12 of whom were non-native English speakers, the overall average score was 91%. So what were the results for the six programs submitted by four independent students/researchers and students from around the world?
As is evident for the table scores ranged from the low 30th percentile i to the high 50s (*after adjustment for a punctuation error in the XML input) so there was no second round for this inaugural contest. As Ortiz commented: while some of the Winograd Schema questions could be handled, much more research is needed to develop systems that can handle these sorts of test. He concluded his report: So now, we look to 2018 where the next Winograd Schema Challenge will be judged at the 2018 AAAI event – and given the rate of innovation and intelligence – could potentially deliver results that take the state of the art in human-machine interaction even further. For more information of the ongoing contest see its page on the Commonsense Reasoning site.
More InformationWinograd Schema Challenge: Can computers reason like humans? L. Morgenstern, E. Davis, and C. Ortiz, “Planning, Executing, and Evaluating the Winograd Schema Challenge,” AI Magazine, Spring 2016. (PDF) E. Davis, L. Morgenstern, and C. Ortiz, "Human tests of materials for the Winograd Schema Challenge 2016" (PDF) Commonsense Reasoning - Winograd Schema Challenge Related ArticlesA Better Turing Test - Winograd Schemas A Flaw In Turing's Test? No A Flaw In Academia No Glittering Prizes For Creative Robots Passing The Turing Test Brings It Into Disrepute A Flaw In Turing's Test? No A Flaw In Academia Loebner Prize Judges Could Easily Identify Chatbots Turing's Test, the Loebner Prize and Chatterbots
To be informed about new articles on I Programmer, sign up for our weekly newsletter, subscribe to the RSS feed and follow us on Twitter, Facebook, Google+ or Linkedin.

Comments
or email your comment to: comments@i-programmer.info |
|||
| Last Updated ( Wednesday, 03 August 2016 ) |