| Robot Dog From Rolling On Floor To Walking In One Hour |
| Written by Mike James | |||
| Sunday, 14 August 2022 | |||
|
Neural networks and reinforcement learning have achieved things that only recently seemed like science fiction, but now we have an example of real machine learning from Pieter Abbeel's Berkeley Robot Learning Lab. A robot dog goes from waving its legs in the air to walking in just one hour and with no external help.
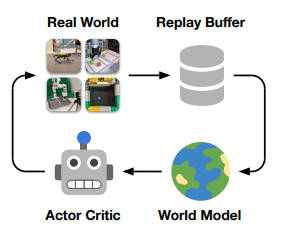
Reinforcement learning is attractive because it is so simple and so direct and it seems to be what happens in the real world. A device makes an action on the world and the world rewards the action according to how well it achieves its objective. When we train a neural network using reinforcement learning we arrange the training environment so that different actions are rewarded according to how much the action moves the device towards its goal. This works really well and neural networks learn to play games like Go, Chess and classic arcade games using this training method. Notice that reinforcement learning only tells the device how well it did, it gives it no idea which direction to move in to improve. What generally happens is that the device explores the environment trying out different actions and preferring actions that provide a reward. The search for an optimal solution is effectively blind and this means that it takes a huge amount of training to get anywhere near the goal. When you think about this there is something wrong. When we work on a behavior via reinforcement learning we don't just randomly select actions. Sometimes we take a break and think it through. What would have happened if instead of action A we had selected action B. With enough imagination we can work out what would have happened and work out what sort of reward might have been provided. We use imagination to extend our training set by running simulations and working out what improves our performance.
This is more or less what a robotic dog at the University of California, Berkeley is doing. It starts out on its back waving its legs in the air but slowly it improves and as it does it learns useful things about its environment. It builds a model and can use the model to find out how to do better without having to go through the same or similar training session over and over again. The algorithm is aptly named "Dreamer" because it is almost like solving problems by dreaming about them. Well, if building a model and using it is like dreaming. This essentially brings planning into the otherwise haphazard application of reinforcement learning. Now that you have some idea what is happening watch the video and be impressed: If you think that the early stages are reminiscent of a small animal learning to walk after just being born, I would agree. This modelling and reinforcement idea seems to be very biologically plausible. And yes, I agree the man with the cardboard tube needs to be reported to the Robot Protection Agency. After the hour was up the robot was pushed gently and it learned to right itself after just ten more minutes. Learning to walk in one hour of real time is a big step forward - pun intended - and it is another example of the current success of neural networks. After failing because of a lack of computing power they have become the mainstay of AI, with huge quantities of data and training. Now in its third age, we have systems of multiple neural networks working with other systems to change from blind training to planned exploration and rapid learning. The team also applied Dreamer to a pick-and-place robotic arm and a wheeled robot. As you might guess they found Dreamer allowed the robots to efficiently learn relevant skills and learn them well. "We applied Dreamer to physical robot learning, finding that modern world models enable sampleefficient robot learning for a range of tasks, from scratch in the real world and without simulators. We also find that the approach is generally applicable in that it can solve robot locomotion, manipulation, and navigation tasks without changing hyperparameters. Dreamer taught a quadruped robot to roll off the back, stand up, and walk in 1 hour from scratch, which previously required extensive training in simulation followed by transfer to the real world or parameterized trajectory generators and given reset policies. We also demonstrate learning to pick and place objects from pixels and sparse rewards on two robot arms in 8–10 hours." The researchers promise to publish their code very soon.
More InformationDayDreamer: World Models for Physical Robot Learning Philipp Wu, Alejandro Escontrela, Danijar Hafner, Ken Goldberg and Pieter Abbeel. University of California, Berkeley https://danijar.com/project/daydreamer/ Related ArticlesA Robot Finally Learns To Walk Pieter Abbeel Wins 2021 ACM Prize In Computing A Robot Learns To Do Things Using A Deep Neural Network Robot Fear Of Falling - South Koreans Win DARPA Robotics Challenge The Virtual Evolution Of Walking The Amazing Dr Guero And His Walking Robots Deep Mimic - A Virtual Stuntman To be informed about new articles on I Programmer, sign up for our weekly newsletter, subscribe to the RSS feed and follow us on Twitter, Facebook or Linkedin. 
Comments
or email your comment to: comments@i-programmer.info
|
|||
| Last Updated ( Sunday, 14 August 2022 ) |