| The Third Age Of AI - Microsoft's Megatron-Turing NLG |
| Written by Mike James | |||
| Wednesday, 03 November 2021 | |||
|
We seem to be moving through a third revolution in AI and it is advancing without too much notice. Part of the reason is that it is difficult to know for sure where the revolution is going. The first AI revolution was at its very start when it became clear that comptures could do things beyond adding up payroll. It quickly discovered a range of techniques including symbolic logic, search and neural networks. The problem with neural networks was that they were difficult to train and didn't really perform well, but they did provide a general approach - even if it didn't work. The second revolution is one we tend to sum up as Deep Learning. Improvements in hardware, and most importantly training data, made it possible to train deep networks with a lot of data. The big surprise was that they worked. We had a really good solution as part of the first revolution but we didn't know it. As Geoffrey Hinton once said "we had the solution all the time". Obviously there were many developments that pushed the subject forward, but once you have proved that deep neural networks actually can learn difficult things they are fairly trivial - convolutional networks, generative networks and so on. The big problem, hardly discussed during the deep learning revolution, was the fact that time-based sequences and patterns were, and are, a problem. To deal with such data you needed a recurrent neural network which use feedback and are very difficult to train. The third revolution is all about finding ways to avoid needing recurrent networks and so we come to the discovery of the transformer and attention. Using this idea we can create deep neural networks that can master temporal associations and hence we can implement natural language systems.
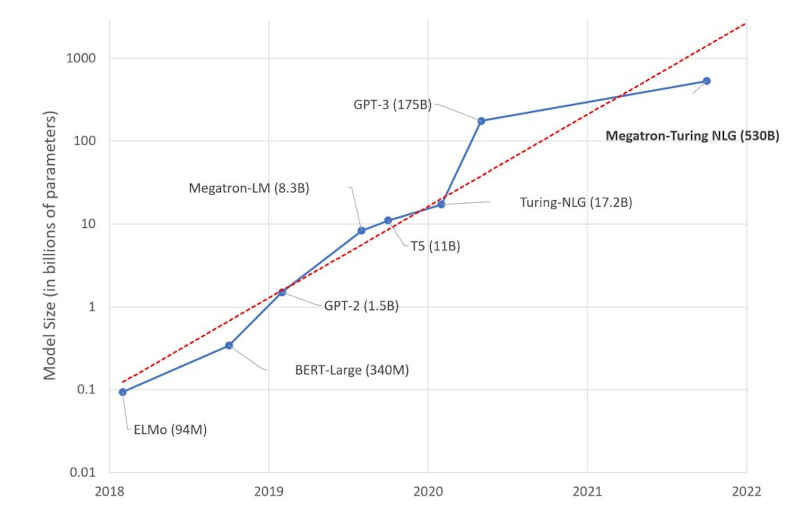
The third revolution is typified by systems like GP-3 that master language tasks so well that they can answer questions, summarize texts, translate languages and write fiction. Networks of this sort are huge. They make the previous deep networks look shallow. The rate at which they are growing in size is also impressive. The third revolution is, like the second, driven by hardware improvements and is driving hardware improvements. The first such network, ELMo, had 94 million parameters. BERT had 340 million, GPT-2 had 1.5 billion parameters and in just a year this jumped to GPT-3's 175 billion paramters. Now, another year on, Microsoft has announced Megatron-Turing NLG, which has 530 Billion parameters! The Microsoft Turing team has created a chart which indicates how fast development has been: This is remarkable! As the Turing team comments: "We live in a time where AI advancements are far outpacing Moore’s law. We continue to see more computation power being made available with newer generations of GPUs, interconnected at lightning speeds. At the same time, we continue to see hyperscaling of AI models leading to better performance, with seemingly no end in sight." Such huge models can only be trained with huge amounts of data and this is why language, which is all over the web, makes such a good training ground. Needless to say, the new network performs better than previous examples using the same approach. The importance however is the way that such a simple model seems to be capable of capturing so much of the structure of the world just from the structure, the statistical structure, of language. Some are of the opinion that this is a fundamental step on the way to general AI - see Trouble At The Heart Of AI? Others are saying that this whole approach is silly and vacuous. It seems that the network is answering questions without understanding anything. It seems to be using nothing but the statistics of language. This is true, but 530 billion parameters to encode a statistical model is something different and in a different class. Perhaps human brains do little more and our belief in our rational intelligence and understanding is just as ephemeral and no more than the statistics of the world encoded into the statistics of language. More InformationRelated ArticlesThe Unreasonable Effectiveness Of GPT-3 Cohere - Pioneering Natural Language Understanding The Paradox of Artificial Intelligence Artificial Intelligence - Strong and Weak To be informed about new articles on I Programmer, sign up for our weekly newsletter, subscribe to the RSS feed and follow us on Twitter, Facebook or Linkedin. 
Comments
or email your comment to: comments@i-programmer.info
|
|||
| Last Updated ( Wednesday, 18 January 2023 ) |