| Google's New Contributions to Landmark Recognition |
| Written by David Conrad |
| Monday, 05 March 2018 |
|
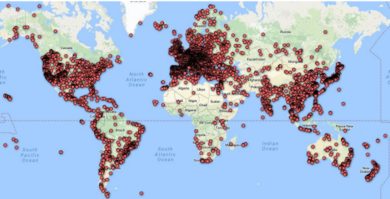
Google Research is releasing Google-Landmarks, a dataset for the recognition of human-made and natural landmarks. It is also open-sourcing Deep Local Features (DELF), an attentive local feature descriptor, suited to the task of landmark recognition. Google Research continues to be among the front runners in computer vision and image classification technology and it also has an excellent track record in making the tools it has developed available for others to use. In their blog post announcing Google-Landmarks, André Araujo and Tobias Weyand, explain their reasons for these latest contributions: In order to continue advancing the state of the art in computer vision, many researchers are now putting more focus on fine-grained and instance-level recognition problems – instead of recognizing general entities such as buildings, mountains and (of course) cats, many are designing machine learning algorithms capable of identifying the Eiffel Tower, Mount Fuji or Persian cats. However, a significant obstacle for research in this area has been the lack of large annotated datasets. The Google-Landmark dataset contains more than 2 million images depicting 30 thousand landmarks from across the world. As this map shows they are distributed across the globe, located in 4,872 cities in 187 countries:
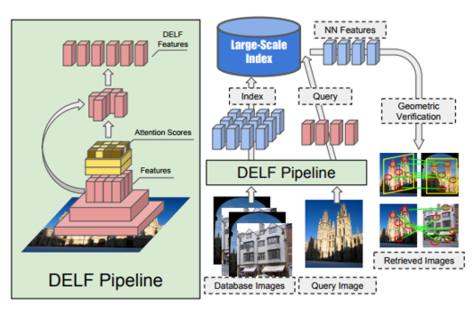
The dataset has been assembled to evaluate DEFL (DEep Local Feature) a new tool based on convolutional neural networks developed at Google and described in a paper co-authored by André Araujo, Tobias Weyand together with fellow Google engineer Jack Sim and two others, Hyeonwoo Noh and Bohyung Han, now affiliated with POSTECH Korea. DELF is a local feature descriptor, that has been designed specifically for large-scale image retrieval applications. The overall architecture of the image retrieval system and its pipeline for extraction and selection of DELF is summarised in this diagram taken from the paper:
The portion highlighted in yellow on the left of the diagram represents an attention mechanism that is trained to assign high scores to relevant features and select the features with the highest scores. Feature extraction and selection can be performed with a single forward pass using the model. The right of the diagram depicts the large-scale feature-based retrieval pipeline. DELF for database images are indexed offline. The index supports querying by retrieving nearest neighbor (NN) features, which can be used to rank database images based on geometrically verified matches. Not only is the new dataset much larger than existing ones with a more diverse set of landmarks it deliberately introduces challenges. According to the researchers: While most images in the existing datasets are landmark-centric, which makes global feature descriptors work well, our dataset contains more realistic images with wild variations including foreground/ background clutter, occlusion, partially out-of-view objects, etc. This illustrates visualization of feature correspondences between images in query and using their approach:
For each pair, query and database images are presented side-by-side. DELF successfully matches landmarks and objects in challenging environment including partial occlusion, distracting objects, and background clutter. Both ends of the red lines denote the centers of matching features. The conclusion to the paper is that: DELF outperforms the state-of-the-art global and local descriptors in the large-scale setting by significant margins.
DELF is on GitHub is the tensorflow/models repository while the Google Landmarks dataset has been released as part of two Kaggle competitions, the Google Landmark Recognition Challenge to label famous (and not-so-famous) landmarks in images and the Google Landmark Retrieval Challenge, the aim of which is to find all images of the specific landmark in a given image. Although both challenges are underway the Entry deadline for both of them is May 15, 2019, which is also the Team Merger deadline, the last day on which participants may join or merge teams. Final submissions have to be made by May 22nd and teams are encouraged to attempt both and to attend the Landmark Recognition Workshop at CVPR 2018. This annual computer vision event, comprising a conference, several associated workshops and short courses takes place this year in Salt Lake City from June 18-22. These competitions are open to all via the Kaggle website, where you'll find details of the rules and prizes on their dedicated Kaggle pages, together with discussions, leader-boards and the Google-supplied training set data and existing forks.
More InformationGoogle Landmark Recognition Challenge on Kaggle Google Landmark Retrieval Challenge on Kaggle Related ArticlesGoogle Has Another Machine Vision Breakthrough? Google Implements AI Landscape Photographer
To be informed about new articles on I Programmer, sign up for our weekly newsletter, subscribe to the RSS feed and follow us on Twitter, Facebook or Linkedin. 
Comments
or email your comment to: comments@i-programmer.info |
| Last Updated ( Tuesday, 13 March 2018 ) |