| Google Discovers That Neural Networks Just Need More Data |
| Written by Mike James | |||
| Monday, 31 July 2017 | |||
|
A recent research report outlines the fact that we just don't feed them enough - data that is. Neural networks simply need more data to be even better.
I'm reminded of the plant in Little Shop of Horrors with the constant refrain "feed me Seymour" or perhaps Johnny Five in the film Short Circuit - "More input!" . I'm also now sure that most of the neural networks I've ever tried to train were undernourished to the point of cruelty. We like to think that we have made big breakthroughs in the design of neural networks, but essentially we as still plugging away at the same ideas that were round in the 1980s and even earlier. There is a very real argument that all that has changed is the availability of large datasets suitable for training networks and the hardware to do the job in a reasonable time.
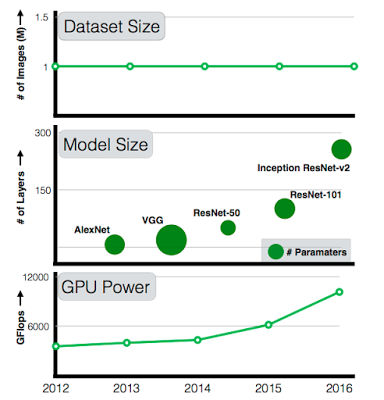
We have explored the effect of model complexity and GPU power over time but dataset size has remained the same.
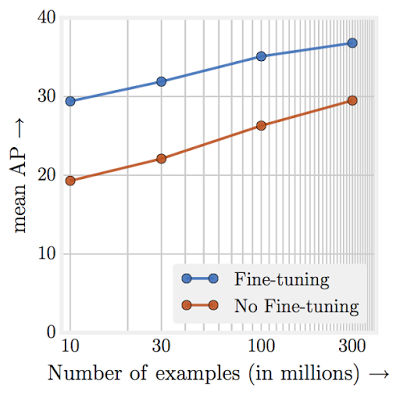
Chen Sun, Abhinav Shrivastava, Saurabh Singh and Abhinav Gupta of Carnegie Mellon and Google Research set out to discover how learning scaled with dataset size. The breakthrough dataset was without a doubt the 1 million labeled images in ImageNet. This was used to train AlexNet back in 2012 and it is still being used to train deeper and more sophisticated networks. The question is why haven't we got bigger datasets? The answer is that it is fairly difficult to extend ImageNet to, say, something 100 times bigger. Such a dataset is needed if we are going to answer the scaling question. The first task was to build a data set consisting of 300 million photos with 18291 categories: "The images are labeled using an algorithm that uses complex mixture of raw web signals, connections between web-pages and user feedback. This results in over one billion labels for the 300M images (a single image can have multiple labels). Of the billion image labels, approximately 375M are selected via an algorithm that aims to maximize label precision of selected images. However, there is still considerable noise in the labels: approximately 20% of the labels for selected images are noisy. Since there is no exhaustive annotation, we have no way to estimate the recall of the labels." Using this data set the performance of various vision tasks was measured versus amount of data. The most important conclusions are: Our first observation is that large-scale data helps in representation learning as evidenced by improvement in performance on each and every vision task we study. Perhaps the most surprising element of our finding is the relationship between performance on vision tasks and the amount of training data (log-scale) used for representation learning. We find that this relationship is still linear! Even with 300M training images, we do not observe any plateauing effect for the tasks studied. That is, the networks could eat even more data if it was available.
What is also interesting is that these were not attempts at creating optimal models. It was observed that you needed deeper models to make use of the additional data, but it is supposed that with more work the performance could be improved. This means that it is likely that the effect of the increased amount of data is an underestimate. Even though they were not optimized the networks produced new state of the art results. So all we have to do to make our neural networks even better is to make them deeper and train them using more data. Here we hit some snags. With the full dataset, training took typically two months using 50 K-80 GPUs. Clearly we have some hardware problems if we are going to take the final suggestion seriously: "We believe that, although challenging, obtaining large scale task-specific data should be the focus of future study. Furthermore, building a dataset of 300M images should not be a final goal - as a community, we should explore if models continue to improve in the regime of even larger (1 billion+ image) datasets." More InformationRevisiting the Unreasonable Effectiveness of Data Revisiting Unreasonable Effectiveness of Data in Deep Learning Era (paper) Related ArticlesDeep Mind's NoisyNet Suggests Random Is Good DIY AI To Sort 2 Metric Tons Of Lego The Shape Of Classification Space Is Mostly Flat Evolution Is Better Than Backprop? To be informed about new articles on I Programmer, sign up for our weekly newsletter, subscribe to the RSS feed and follow us on Twitter, Facebook or Linkedin. 
Comments
or email your comment to: comments@i-programmer.info |
|||
| Last Updated ( Monday, 31 July 2017 ) |