| Investigating Bias In AI Language Learning |
| Written by Sue Gee | |||
| Monday, 17 April 2017 | |||
|
A new study has revealed that AI systems, such as Google Translate, acquire the same cultural biases as humans.While this isn't a surprising finding, it comes as a cause for concern and remedial action. The research published in Science, the weekly journal of the American Association for the Advancement of Science comes from the Center for Information Technology (CITP) at Princeton University. Arvind Narayanan, an assistant professor of computer science at Princeton affiliated faculty member to the CITP explained the rationale for this research: "Questions about fairness and bias in machine learning are tremendously important for our society. We have a situation where these artificial intelligence systems may be perpetuating historical patterns of bias that we might find socially unacceptable and which we might be trying to move away from." The tool used for research into human biases is the Implicit Association Test which measures response times (in milliseconds) by subjects asked to pair word concepts displayed on a computer screen. Response times are far shorter, for concepts perceived as similar than for those regarded dissimilar. The Princeton team developed a similar way to measure biases in AI systems that acquire language from human texts. Rather than measuring lag time, however, their Word-Embedding Association Test uses associations between words, analyzing roughly 2.2 million words in total. In particular they relied on GloVe (Global Vectors for Word Representation) an open source program developed by Stanford researchers for measuring linguistic or semantic similarity of words in terms of co-occurrence and proximity. They used this to approach to look at words like "programmer, engineer, scientist" and "nurse, teacher, librarian" alongside two sets of attribute words, such as "man, male" and "woman, female," looking for evidence of the kinds of biases humans can unwittingly possess. The AAS released this video in which the three authors of Semantics derived automatically from language corpora contain human-like biases, Aylin Caliskan, Joanna Bryson and Arvind Narayanan explain their approach and the results of the study which revealed race and gender biases in AI systems:
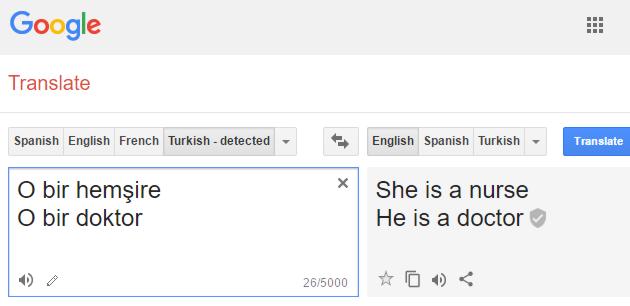
In the video Aylin Caliskan explains that female names are generally associated with family terms, whereas male names are associated with career terms and demonstrates how AI perpetuates gender stereotypes using Google Translate and Turkish, a language that has three pronouns - he, she and it. So when you use the gender neutral pronoun in the pair of sentences; "it is a doctor"; "it is a nurse" typed in in Turkish and ask for translation to English, here is what happens:
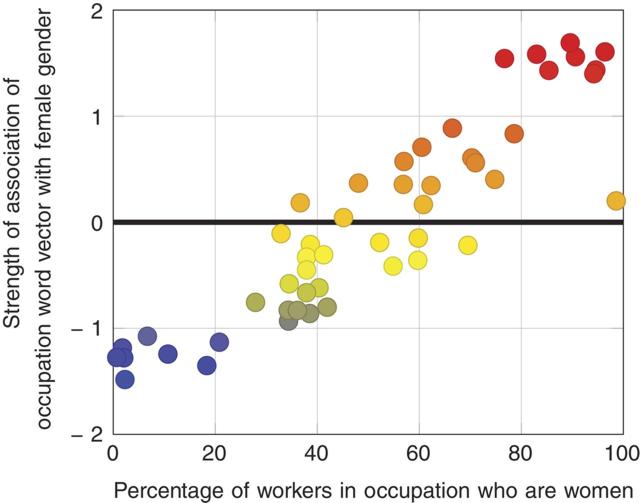
He is a doctor/She is a nurse Joanna Bryson also points out that while machine learning programs show the same prejudice as humans in associating females with domestic roles, they also accurate at predicting the actual proportion of women in occupation types when compared to U.S. Bureau of Labor Statistics and revealed in this scatter plot from the Science article:
In an interview with the Guardian newspaper Bryson says: “A lot of people are saying this is showing that AI is prejudiced. No. This is showing we’re prejudiced and that AI is learning it.” She warned that AI has the potential to reinforce existing biases because, unlike humans, algorithms may be unequipped to consciously counteract learned biases saying, “A danger would be if you had an AI system that didn’t have an explicit part that was driven by moral ideas, that would be bad." In the conclusion to the article in Nature reiterates this idea and comes up with some suggestions for countering bias: if machine-learning technologies used for, say, résumé screening were to imbibe cultural stereotypes, it may result in prejudiced outcomes. We recommend addressing this through the explicit characterization of acceptable behavior. One such approach is seen in the nascent field of fairness in machine learning, which specifies and enforces mathematical formulations of nondiscrimination in decision-making. Another approach can be found in modular AI architectures, such as cognitive systems, in which implicit learning of statistical regularities can be compartmentalized and augmented with explicit instruction of rules of appropriate conduct . Certainly, caution must be used in incorporating modules constructed via unsupervised machine learning into decision-making systems. So while there may be some situations in which unsupervised learning can reveal interesting and insightful results,where machine learning is let loose on society it needs to be supervised into applying acceptable norms and not just the existing ones.
More Information AI systems exhibit gender and racial biases when learning language Related ArticlesVisualizing the Gender Gap in Computer Science Stack Overflow Developer Characteristics
To be informed about new articles on I Programmer, sign up for our weekly newsletter, subscribe to the RSS feed and follow us on Twitter, Facebook or Linkedin. 
Comments
or email your comment to: comments@i-programmer.info
|
|||
| Last Updated ( Monday, 17 April 2017 ) |