|
The big improvements in Hadoop 2.x were the introduction of the YARN framework for job scheduling and cluster resource management, and high availability for the Hadoop Distributed Filing system. We explore how to configure high availability clusters using two architectures.
This is an excerpt from the book, Modern Big Data Processing with Hadoop, a comprehensive guide to design, build and execute effective Big Data strategies using Hadoop from Packt Publishing.
Single point failure in Hadoop 1.x architecture
Hadoop 1.x started with the architecture of a single NameNode. All DataNodes used to send their block reports to that single NameNode. There was a secondary NameNode in the architecture, but its sole responsibility was to merge all edits to FSImage.
With this architecture, the NameNode became the single point of failure (SPOF). Since it has all the metadata of all the DataNodes of the Hadoop cluster, in the event of NameNode crash, the Hadoop cluster becomes unavailable till the next restart of NameNode repair. If the NameNode cannot be recovered, then all the data in all the DataNodes would be completely lost. In the event of shutting down NameNode for planned maintenance, the HDFS becomes unavailable for normal use. Hence, it was necessary to protect the existing NameNode by taking frequent backups of the NameNode filesystem to minimize data loss.
Improved High availability in Hadoop 2.x
In order to overcome HDFS high availability (HA) problems and make NameNode a SPOF, the architecture has changed. The new architecture provides a running of two redundant NameNodes in the same cluster in an active/passive configuration with a hot standby. This allows a fast failover to a new NameNode in the event of a machine crashing, or a graceful administrator-initiated failover for the purpose of planned maintenance.
The following two architectural options are provided for HDFS HA:
For a detailed overview of HDFS clusters including NameNodes and YARN, check out ‘What makes Hadoop so revolutionary?’
HDFS HA cluster using NFS
The following diagram depicts the HDFS HA cluster using NFS for shared storage required by the NameNodes architecture:
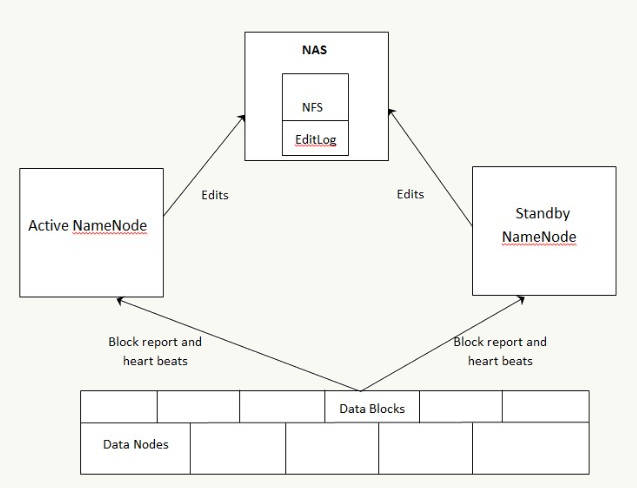
Key points to consider about HDFS HA using shared storage architecture:
-
In the cluster, there are two separate machines: active state NameNode and standby state NameNode.
-
At any given point in time, one-and-only, one of the NameNodes is in the active state, and the other is in the standby state.
-
The active NameNode manages the requests from all client DataNodes in the cluster, while the standby remains a slave.
-
All the DataNodes are configured in such a way that they send their block reports and heartbeats to both the active and standby NameNodes.
-
The standby NameNode keeps its state synchronized with the active NameNode.
-
Active and standby nodes both have access to a filesystem on a shared storage device (for example, an NFS mount from a NAS)
-
When a client makes any filesystem change, the active NameNode makes the corresponding change (edits) to the edit log file residing on the network shared directory.
-
The standby NameNode makes all the corresponding changes to its own namespace. That way, it remains in sync with the active NameNode.
-
In the event of the active NameNode being unavailable, the standby NameNode makes sure that it absorbs all the changes (edits) from the shared network directory and promotes itself to an active NameNode.
-
The Hadoop administrator should apply the fencing method to the shared storage to avoid a scenario that makes both the NameNodes active at a given time. In the event of failover, the fencing method cuts the access to the previous active NameNode to make any changes to the shared storage to ensure smooth failover to standby NameNode. After that, the standby NameNode becomes the active NameNode.
Configuring HA NameNodes with shared storage
Add the following properties to the hdfs-site.xml:
|
Property
|
Value
|
|
dfs.nameservices
|
cluster_name
|
|
dfs.ha.namenodes.cluster_name
|
NN1, NN2
|
|
dfs.namenode.rpc-address.cluster_name.NN1
|
machine1:8020
|
|
dfs.namenode.rpc-address.cluster_name.NN2
|
machine2:8020
|
|
dfs.namenode.http-address.cluster_name.NN1
|
machine1:50070
|
|
dfs.namenode.http-address.cluster_name.NN2
|
machine2:50070
|
|
dfs.namenode.shared.edits.dir
|
file:///mnt/filer1/dfs/ha-name-dir-shared>
|
|
dfs.client.failover.proxy.
provider.cluster_name
|
org.apache.hadoop.hdfs.server.
namenode.ha.
ConfiguredFailoverProxyProvider
|
|
dfs.ha.fencing.methods
|
sshfence
|
|
dfs.ha.fencing.ssh.private-key-files
|
/home/myuser/.ssh/id_rsa
|
|
dfs.ha.fencing.methods
|
sshfence([[username][:port]])
|
|
dfs.ha.fencing.ssh.connect-timeout
|
30000
|
Add the following properties to core-site.xml:
|
Property
|
Value
|
|
fs.defaultFS
|
hdfs://cluster_name
|
HDFS HA cluster using the quorum journal manager
The following diagram depicts the quorum journal manager (QJM) architecture to share edit logs between the active and standby NameNodes:
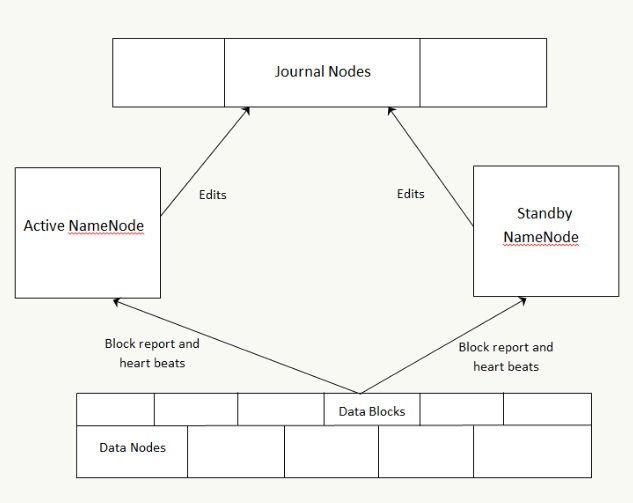
Key points to consider about HDFS HA using the QJM architecture:
-
In the cluster, there are two separate machines—the active state NameNode and standby state NameNode.
-
At any point in time, exactly one of the NameNodes is in an active state, and the other is in a standby state.
-
The active NameNode manages the requests from all client DataNodes in the cluster, while the standby remains a slave.
-
All the DataNodes are configured in such a way that they send their block reports and heartbeats to both active and standby NameNodes.
-
Both NameNodes, active and standby, remain synchronized with each other by communicating with a group of separate daemons called JournalNodes (JNs).
-
When a client makes any filesystem change, the active NameNode durably logs a record of the modification to the majority of these JNs.
-
The standby node immediately applies those changes to its own namespace by communicating with JNs.
-
In the event of the active NameNode being unavailable, the standby NameNode makes sure that it absorbs all the changes (edits) from JNs and promotes itself as an active NameNode.
-
To avoid a scenario that makes both the NameNodes active at a given time, the JNs will only ever allow a single NameNode to be a writer at a time. This allows the new active NameNode to safely proceed with failover.
Configuring HA NameNodes with QJM
Add the following properties to hdfs-site.xml:
|
Property
|
Value
|
|
dfs.nameservices
|
cluster_name
|
|
dfs.ha.namenodes.cluster_name
|
NN1, NN2
|
|
dfs.namenode.rpc-address.cluster_
name.NN1
|
machine1:8020
|
|
dfs.namenode.rpc-address.cluster_
name.NN2
|
machine2:8020
|
|
dfs.namenode.http-address.cluster_name.NN1
|
machine1:50070
|
|
dfs.namenode.http-address.cluster_name.NN2
|
machine2:50070
|
|
dfs.namenode.shared.edits.dir
|
qjournal://node1:8485;node2:8485;
node3:8485/cluster_name
|
|
dfs.client.failover.proxy.
provider.cluster_name
|
org.apache.hadoop.hdfs.server.
namenode.ha.
ConfiguredFailoverProxyProvider
|
|
dfs.ha.fencing.methods
|
sshfence
|
|
dfs.ha.fencing.ssh.private-key-files
|
/home/myuser/.ssh/id_rsa
|
|
dfs.ha.fencing.methods
|
sshfence([[username][:port]])
|
|
dfs.ha.fencing.ssh.connect-timeout
|
30000
|
Add the following properties to core-site.xml:
|
Property
|
Value
|
|
fs.defaultFS
|
hdfs://cluster_name
|
|
dfs.journalnode.edits.dir
|
/path/to/journal/node/local/datat
|
It's very important to know that the above two architectures support only manual failover. In order to do automatic failover, we have to introduce two more components a ZooKeeper quorum, and the ZKFailoverController (ZKFC) process, and more configuration changes.
Important architecture points
-
Each NameNode, active and standby, runs the ZKFC process.
-
The state of the NameNode is monitored and managed by the ZKFC.
-
The ZKFC pings its local NameNode periodically to make sure that that the NameNode is alive. If it doesn't get the ping back, it will mark that NameNode unhealthy.
-
The healthy NameNode holds a special lock. If the NameNode becomes unhealthy, that lock will be automatically deleted.
-
If the local NameNode is healthy, and the ZKFC sees the lock is not currently held by any other NameNode, it will try to acquire the lock. If it is successful in acquiring the lock, then it has won the election. It is now the responsibility of this NameNode to run a failover to make its local NameNode active.
Configuring automatic failover
Add the following properties to hdfs-site.xml to configure automatic failover:
|
Property
|
Value
|
|
dfs.ha.automatic-failover.enabled
|
true
|
|
ha.zookeeper.quorum
|
zk1:2181, zk2:2181, zk3:2181
|
- This article is excerpt from the book, Modern Big Data Processing with Hadoop, by V. Naresh Kumar, and Prashant Shindgikar, published by Packt Publishing.
Use the code ORIPA10 at checkout to obtain eBook retail price of $10 (valid till May 31, 2018).

To be informed about new articles on I Programmer, sign up for our weekly newsletter, subscribe to the RSS feed and follow us on Twitter, Facebook or Linkedin.
Related Articles
Reading Your Way Into Big Data
Hadoop 2 Introduces YARN
|