| Kinect comes to Smart Phones? |
| Written by Harry Fairhead |
| Friday, 06 January 2012 |
|
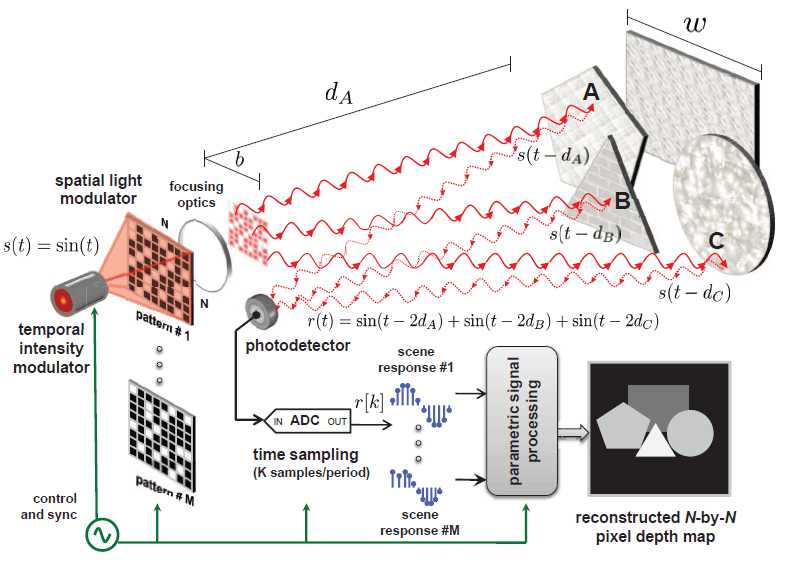
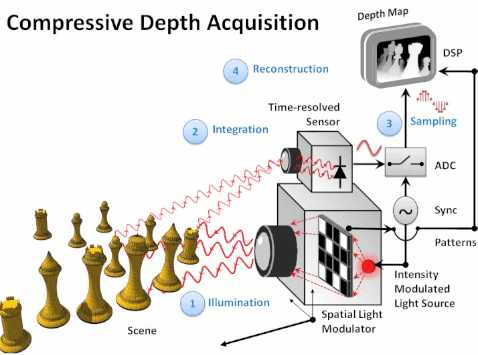
Researchers have come up with a fast, accurate, cheap way to measure a depth field. It also promises portable depth detectors small enough to fit in a mobile phone. Ever since the Kinect hit the market there is no doubt about the utility of getting 3D depth input. You can use it to implement whole body tracking, gesture input, robot control, AR, telepresence and more. The only problem is that the Kinect is slightly on the large size and, while it has been used in mobile robots, the idea of connecting it to a phone is out of the question - but just think of the uses of a 3D equipped phone! The traditional way of getting 3D input is to use LIDAR or time of flight systems. This basically works like a radar in that it bounces light off surfaces and measures the round trip time to work out how far the surface is away. This works and is accurate but it is slow and expensive. It is slow because the laser used to generate the timed light pulse has to be scanned across the scene. This, by the way, is not how the Kinect works - it uses a different principle called structured light.You can speed up the LIDAR scanner by using multiple sources and sensors - one per pixel - and so avoid the need to scan but this is expensive and slow. Now researchers at MIT think they have a new way to measure a depth field and it is fast, accurate, cheap and very small. CoDAC, Compressive Depth Acquisition Camera, is a time of flight distance measurement system, but it uses a single light source and detector and it doesn't have to scan the scene. This sounds magical and in many ways it is. The "Compressive" part of the title refers to the commonly observable fact that a depth map is much more redundant than a reflectance photo of the same scene. This means it contains less information and can be compressed more than a photo. Another way to put this is to say that even though you plot many pixels in a depth map there aren't many discontinues in depth and large numbers of pixels have virtually the same depth. The CoDAC system uses a single light source, but it passes through a spatial light modulator which effectively projects a random array of beams onto the scene. All of the light returned to the camera is focused onto a single sensor. You can't extract the distances from this data, which contains return signals from all of the locations that the beam illuminates, because the return times don't identify which beam they apply to.
If, however, you repeat the process with a different random mask, you can process the accumulated data to work out the depths at each pixel. This is a bit like computer tomography where a set of shadows taken at different angles can be processed to extract the internal structure of the object casting the shadows. Unscrambling the depth data from multiple random samples isn't easy unless you make a simplifying assumption. In this case you have to assume that the scene is made up of flat surfaces and adjacent pixels vary in depth in a linear fashion. With this assumption you can solve the problem and compute the depth field. You can see how it all works in the video - but it does get a little complicated towards the end.
At the moment CoDAC is only at the proof of concept phase and it has only been implemented at a 64x64 resolution. Even so the resolution was less than 1cm (about 2mm) despite the pulse time of the laser diode being so long that it could achieve an accuracy of no more than 21cm. The researchers also found that the number of random patterns needed was about 5% of the number of pixels - due to the information redundancy.
It really is a lesson in what you can do with the right algorithm! It will be a little time before a commercial system is available - at the moment the MIT team is working on extending the method to curved surfaces - but Intel has already invested $100,000 as part of its innovation Fellowship program. Having portable depth detectors small enough to fit in a mobile phone really would open up a whole new world of apps. Information
Compressive Depth Acquisition Camera (CoDAC) Project Page
Comments
or email your comment to: comments@i-programmer.info
To be informed about new articles on I Programmer, subscribe to the RSS feed, follow us on Google+, Twitter, Linkedin or Facebook or sign up for our weekly newsletter.

|
| Last Updated ( Friday, 06 January 2012 ) |