| TPU Better Than GPU |
| Written by Mike James |
| Thursday, 06 April 2017 |
|
Nearly a year ago we commented that the TPU - The Tensor Processing Unit - might be Google's big advantage in AI. Now we have some performance figures that suggest that this is very true. If you want to do AI, you probably do need a TPU rather than a GPU. For our previous report see TPU Is Google's Seven Year Lead In AI.
Google has been using the TPU since 2015 and it is designed to make computations defined using Tensor Flow go much faster. Most other AI researchers make use of GPUs, but these were originally designed to implement graphics pipelines and, while much faster, can hardly be expected to be the best hardware for the job. Strangely even NVIDA, who could create special hardware, tends to use its high power GPUs when it is trying out AI. The information that Google has now released does suggest that using custom hardware like the TPU is the way to go if you are trying to train a neural network:
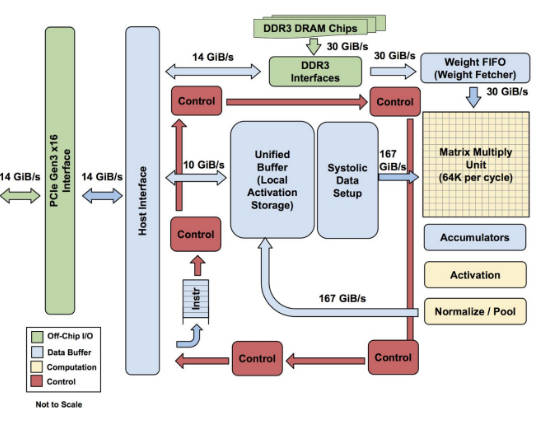
A paper giving more details explains that the TPUs are being used for inference, that is a trained neural network is presented with an input vector and this propagates forward to give an output vector - no training is involved. An eye opening statistic is that the models have between 5 and 100 million weights.
Google created the TPU to solve the problem of putting neural networks into production systems: "The need for TPUs really emerged about six years ago, when we started using computationally expensive deep learning models in more and more places throughout our products. The computational expense of using these models had us worried. If we considered a scenario where people use Google voice search for just three minutes a day and we ran deep neural nets for our speech recognition system on the processing units we were using, we would have had to double the number of Google data centers!"
"TPUs are behind every search query; they power accurate vision models that underlie products like Google Image Search, Google Photos and the Google Cloud Vision API; they underpin the groundbreaking quality improvements that Google Translate rolled out last year; ..." The surprising point here is "behind every search query". You could well guess that the TPU would be central to obviously AI-oriented tasks such as image search and translation - but it's a stretch to think one is involved in "every search query". Does this mean that RankBrain, see -RankBrain - AI Comes To Google Search, or some other neural network is involved in every Google search? Another fairly easy-to-guess use is: "...and they were instrumental in Google DeepMind's victory over Lee Sedol, the first instance of a computer defeating a world champion in the ancient game of Go." It is puzzling, but welcome, that Google has shared so much of its AI with the rest of us, despite raising some worries by patenting some very basic techniques. Perhaps it doesn't matter that it is well known how the magic is achieved if only Google and other large concerns have the hardware to make it happen.
More InformationQuantifying the performance of the TPU, our first machine learning chip In-Datacenter Performance Analysis of a Tensor Processing Unit Related ArticlesTPU Is Google's Seven Year Lead In AI RankBrain - AI Comes To Google Search TensorFlow 0.8 Can Use Distributed Computing Google Tensor Flow Course Available Free How Fast Can You Number Crunch In Python Google's Cloud Vision AI - Now We Can All Play TensorFlow - Googles Open Source AI And Computation Engine Google Open Sources Accurate Parser - Parsey McParseface
To be informed about new articles on I Programmer, sign up for our weekly newsletter, subscribe to the RSS feed and follow us on Facebook or Linkedin. 
Comments
or email your comment to: comments@i-programmer.info |
| Last Updated ( Thursday, 06 April 2017 ) |