| First Hybrid Open-Source RDBMS Powered By Hadoop and Spark |
| Written by Nikos Vaggalis | |||
| Friday, 22 July 2016 | |||
|
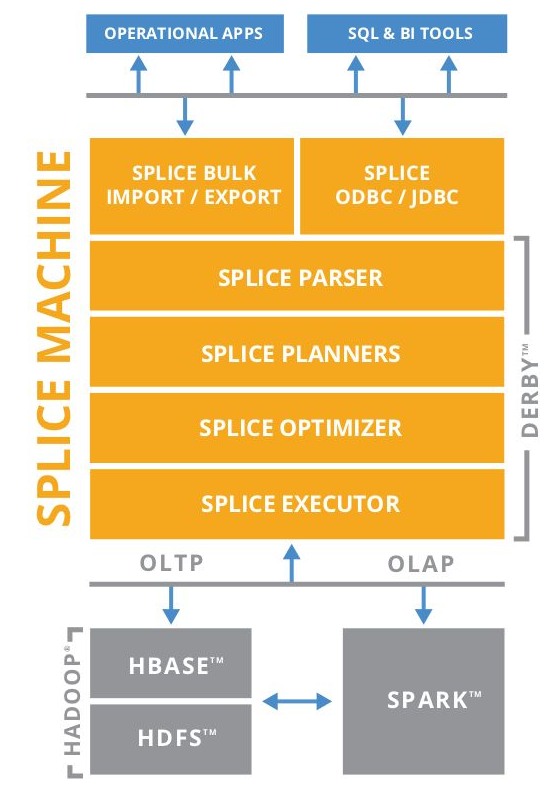
Splice Machine is a novel attempt to merge the best parts of the traditional relational database management systems and their NoSQL counterparts with distributed and in-memory computing based on Hadoop and Spark. Traditional RDBMS find it tough when faced with massive amounts of data, which they typically handle by scaling up, albeit expensively. Another side effect of the sheer volume of data accumulating from the likes of social media and mobile devices, is that OLTP and OLAP queries carry high performance hits that subsequently have detrimental effects on real time analysis and instant decision making. NoSQL systems might have the answer to the cheap and effective handling of that kind of volume by scaling horizontally rather than up, on commodity hardware. But in comparison to the the traditional RDBMS solution, NoSQL falls short in offering support for ANSI SQL and transactional processing. Then in-memory databases, despite the fact that they offer the best value for money, also fall short when memory fills up under the load of terrabytes of data, at which point they typically drop the queries they cannot handle, providing for neither fail safety nor consistency. The answer to these problems is in integrating a number of state of the art technologies in a single package with a "hyper"-hybrid approach. That attempt is Splice Machine and comprises: HBase and Hadoop They solve the scaling problem of working under the load of petabytes, at the same time providing failover guarantees. Apache Derby
Their interoperation, based on sophisticated procedures, enables a true RDBMS with MVCC and ACID on Hadoop, capable of doing realtime on the fly analysis and updates on massive and distributed data volumes, creating a new breed of database technologies. Don't forget the open source advantage. Very recently Splice Machine went open source, following a trend already set by other DBMSs like Actian's Ingres, in an attempt to expand its adoption and client base, form a community around it and make the process of getting hold of it and testing it much easier. Splice Machine is available in both the Community and Enterprise editions, with the Community one being free and with unrestricted SQL, while the Enterprise one includes devops features, such as backup, encryption, and security, plus future features like Oracle PL/SQL wire-compatibility (Fall 2016) and active-active replication (in 2017). Official support comes with the Enterprise edition only. Developers will be able to test and deploy the Community Edition at scale, thanks to a Amazon Web Services cloud-based sandbox launched earlier this week. This gives the ability to put the new open-source 2.0 Community Edition through tests ranging from small to enterprise scale, by initiating clusters in minutes. If this is not already enough to persuade you in trying out Splice Machine, then the following benefits when compared to • 10-20x faster – leverages HBase, the distributed NoSQL DB, as well as in-memory cluster computing from Spark
More InformationRelated ArticlesActian Ingres 11 Technical Preview
To be informed about new articles on I Programmer, sign up for our weekly newsletter,subscribe to the RSS feed and follow us on, Twitter, Facebook, Google+ or Linkedin.

Comments
or email your comment to: comments@i-programmer.info
|
|||
| Last Updated ( Friday, 22 July 2016 ) |