| IBM Netezza - Data analysis in hardware |
| Written by Kay Ewbank | |||
| Thursday, 23 June 2011 | |||
|
IBM has launched a data analysis device that can store up to 10 petabytes of data and analyse it within minutes. This is first appliance developed with Netezza which IBM bought last year. The IBM Netezza High Capacity Appliance creates a query-able archive and scales to more than 10 petabytes of user data capacity. it is envisaged as a disaster recovery target for multiple systems, advanced analytics on massive data or data warehousing information lifecycle management.
It is based on an asymmetric massively parallel processing (AMPP) architecture which, according to the whitepaper describing the device adheres to a fundamental computer science principle: when operating on large data sets, do not move data unless absolutely necessary.
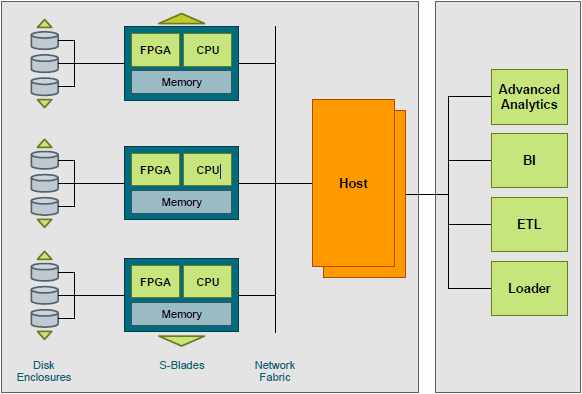
AMPP architecture
The device uses Field Programmable Gate Arrays (FPGAs) to filter out extraneous data as early in the data stream as possible and as fast as data streams off the disk. This process of data elimination close to the data source removes I/O bottlenecks and frees up downstream components such as the CPU, memory, and network from processing superfluous data, thus having a significant multiplier effect on system performance. The Netezza platform starts with units as small as a few hundred gigabytes, and the use of open blade-based components allows the disk-processor-memory ratio to be modified to take account of the needs for concentrating on performance or storage. The same architecture also supports memory-based systems that, according to the whitepaper, provide extremely fast, real-time analytics for mission-critical applications. Netezza software components include a parallel optimizer that transforms queries to run more efficiently; an intelligent scheduler, and Turbocharged Snippet Processors that execute multiple queries and complex analytics functions concurrently. This Guided Tour to the Netezza Twin-Fin gives an overview of the hardware and architecture of the device and lets you appreciate its size - just imagine it in blue rather than green! The optimizer makes use of all the MPP nodes in the system to gather detailed, up-to-date statistics on every database table referenced in a query. The compiler converts the query plan into executable code segments, called snippets, which are query segments executed by Snippet Processors in parallel across all the data streams in the appliance. Each snippet has two elements: compiled code executed by individual CPU cores and a set of FPGA parameters to customize the FAST engines filtering for that particular snippet. This snippet-by-snippet customization allows the Netezza platform to provide, in effect, a hardware configuration optimized on the fly for individual queries.

|
|||
| Last Updated ( Thursday, 23 June 2011 ) |