| NASA’s Asteroid Tracker Challenge |
| Written by Sue Gee | |||
| Friday, 25 July 2014 | |||
|
A 14-day Marathon Match with $15,000 in prizes at stake starts today. Join other competitors to devise algorithms to help NASA track asteroids that would cause cataclysmic devastation were they to impact Earth. This contest is a new phase of NASA's Asteroid Grand Challenge being run on Appirio's [topcoder] platform.
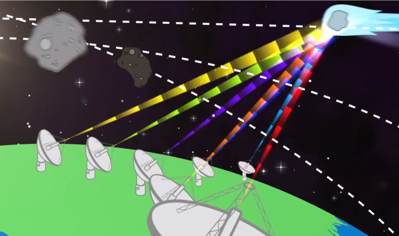
In this part of the ongoing challenge, competitors are being asked to optimize the use of an array of radar dishes when tracking Near Earth Objects (NEO) from the time they become visible over the horizon till the point at which they cease to be visible. This tracking allows scientists to gather information from each object such as composition, spin rate, among other properties.
Or to put it as explained in the video: We need you help figuring out the best combination of subarrays to cover the most tracks with the best quality and power possible. In Phase One, which is a Marathon match from July 25 to August 8, the goal is to find an optimizing algorithm that selects the best set of subarrays to track one or more objects.
Contestants are asked to devise the optimum subarray selection per set of object tracks provided in a predefined configuration using a fixed number of dishes The data provided is the number of radar dishes, configuration of the array and properties of each radar dish. Data is also supplied for objects and their trajectories over a specific time period and the time needed to accurately track an object. A later phase of the Asteroid Grand Challenge will build on the results and will focus optimal optimizing configuration and looking at placement of additional dishes.
To join in this challenge first join the [topcoder] community, which already has over 600,000 members. Registration is free and you can immediately start to enter its contests, which fall into three categories: Develop; Design and Data Science. As cash rewards you can earn Reputation Points. New challenges are constantly added and they have scoreboards, leaderboards and discussion boards.
More InformationAsteroid Tracker marathon Match NASA's Asteroid Grand Challenge Series on TopCoderRelated ArticlesNASA's Asteroid Grand Challenge NASA Contributes Mission to Kerbal Space Program Top Coder And CloudSpokes Join Forces
To be informed about new articles on I Programmer, install the I Programmer Toolbar, subscribe to the RSS feed, follow us on, Twitter, Facebook, Google+ or Linkedin, or sign up for our weekly newsletter.

Comments
or email your comment to: comments@i-programmer.info |
|||
| Last Updated ( Friday, 25 July 2014 ) |