| Spark 1.4 Released |
| Written by Kay Ewbank | |||
| Tuesday, 16 June 2015 | |||
|
Spark 1.4 has been released with an R API targeted towards data scientists.
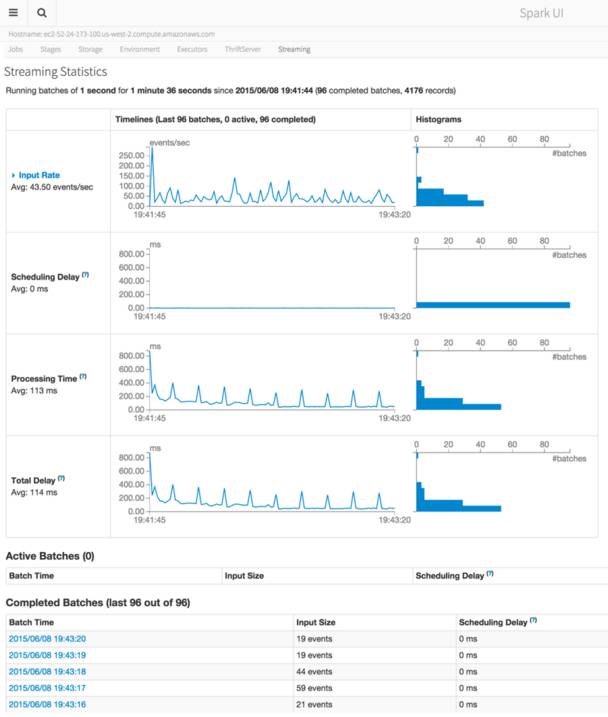
The new version also adds new features to Spark’s DataFrame API. Spark is an open source processing engine for data processing. It comes packaged with support for ETL, interactive queries (SQL), advanced analytics such as machine learning, and streaming over large datasets. The R API, SparkR, can be used to create SparkR DataFrames from “local” R data frames, or from any Spark data source such as Hive, HDFS, Parquet or JSON. SparkR DataFrames support all Spark DataFrame operations including aggregation, filtering, grouping, summary statistics, and other analytical functions. They also support mixing-in SQL queries, and converting query results to and from DataFrames. Writing about the new version on the Databricks Spark blog, Patrick Wendell says that because SparkR uses the Spark’s parallel engine underneath, operations take advantage of multiple cores or multiple machines, and can scale to data sizes much larger than standalone R programs. Alongside the R API, the new release adds window functions to Spark SQL and in Spark’s DataFrame library, making it possible to compute statistics over window ranges. The developers have added a number of new features for DataFrames, including enriched support for statistics and mathematical functions (random data generation, descriptive statistics and correlations, and contingency tables), as well as functionalities for working with missing data. Project Tungsten is also shipped with this version of Spark. Project Tungsten is designed to make Dataframe operations execute quickly, and this version has only the initial pieces with more features to be added in the future. The current release has serializer memory use and options to enable fast binary aggregations. The machine learning (ML) pipelines API that was introduced in Spark 1.2 has been changed from an alpha version to one that will be stable going forward. Using pipelines means users can set up machine learning workloads that include many steps, such as data pre-processing, feature extraction and transformation, model fitting, and validation stages. New features have also been added to the pipelines API, with feature transformers such as RegexTokenizer, OneHotEncoder, and VectorAssembler, and new algorithms like linear models with elastic-net and tree models. The other major improvement to Spark is the addition of visual debugging and monitoring utilities to give developers a visual insight into the runtime behavior of Spark applications, and an application timeline viewer that profiles the completion of stages and tasks inside a running program.
Wendell says that Spark 1.4 also exposes a visual representation of the underlying computation graph (or “DAG”) that is tied directly to metrics of physical execution.
More InformationRelated Articles
To be informed about new articles on I Programmer, install the I Programmer Toolbar, subscribe to the RSS feed, follow us on, Twitter, Facebook, Google+ or Linkedin, or sign up for our weekly newsletter.

Comments
or email your comment to: comments@i-programmer.info |
|||
| Last Updated ( Tuesday, 16 June 2015 ) |