| Apache Spark With Structured Streaming |
| Written by Kay Ewbank | |||
| Friday, 21 July 2017 | |||
|
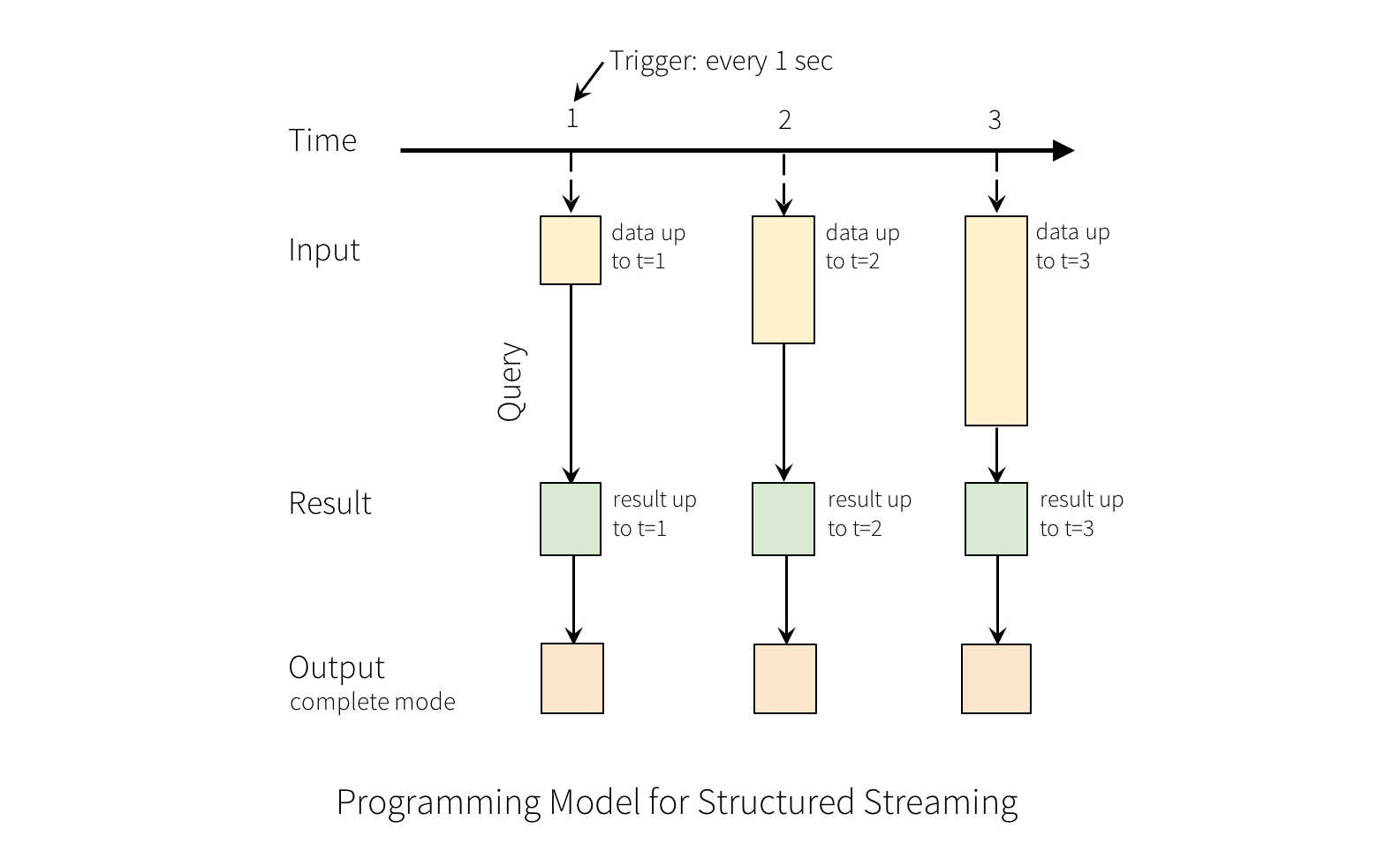
Apache Spark 2.2 has been released with Structured Streaming no longer experimental. The accompanying release of PySpark is also available in pypi. Spark is Apache's data processing engine for processing and analyzing large amounts of data. It is implemented in Scala and Java, runs on a cluster, and so long as the cluster has enough main memory to hold the data being analyzed, offers excellent performance. It improves on Hadoop MapReduce performance, running programs up to 100 times faster in memory and ten times faster on disk, according to Apache. An ever increasing range of projects can run on top of Spark, including GraphX for graph analysis,Spark SQL for querying structured data inside Spark programs; Spark Streaming for scalable fault-tolerant streaming applications; and MLib for machine learning algorithms. Apache Spark 2.2.0 is the third release on the 2.x line. The headline improvement is the removal of the experimental tag from Structured Streaming.This is an API introduced last year in an experimental version. The API lets you express a streaming computation the same way you would express a batch computation on static data.
The Spark SQL engine will take care of running it incrementally and continuously and updating the final result as streaming data continues to arrive. You can use the Dataset/DataFrame API in Scala, Java, Python or R to express streaming aggregations, event-time windows, and stream-to-batch joins. Structured Streaming provides a straightforward way to build end-to-end streaming applications that react to data in real time, and where aspects such as query serving or interaction with batch jobs are handled as part of the streaming application. The new release also adds Apache Kafka 0.10 support for both reading and writing using the streaming and batch APIs.New functionality has also been added to SparkR, Python, MLlib, and GraphX. MLib and GraphX have new algorithms for locality sensitive hashing, multiclass logistic regression, and personalized pageRank. SparkR now supports a number of distributed algorithms, specifically
The other main improvement is that PySpark (The Spark Python API that exposes the Spark programming model to Python) is now available in pypi and can be installed using pip install.
More InformationStructured Streaming Guide for Spark Related ArticlesSpark BI Gets Fine Grain Security Apache Spark Technical Preview To be informed about new articles on I Programmer, sign up for our weekly newsletter, subscribe to the RSS feed and follow us on Twitter, Facebook or Linkedin.

Comments
or email your comment to: comments@i-programmer.info |