| SQL At Hadoop Scale |
| Written by Kay Ewbank |
| Monday, 08 September 2014 |
|
Improvements to the Hive engine have been announced by Hortonworks. Stinger.next is intended to deliver enterprise SQL with sub-second query response time and to scale from Gigabytes to Petabytes.
Hortonworks has announced their plans for more improvements to the Hive interface for Hadoop. The plans build on their Stinger Initiative, which was launched in April as an expansion on the Hive engine to allow for interactive SQL queries at the Hadoop scale. This video gives some background on Hive and the Stinger initiative:
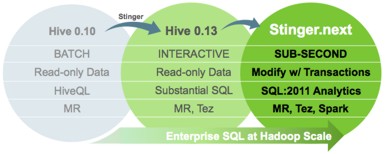
Hortonworks has now announced the next set of objectives for Stinger, Stinger.next, which are aimed at increasing the speed, scale and breadth of SQL support in Hive.
The plan is to roll out Stinger.next in incremental installments. Three main areas are planned, each being added in its own installment. The three areas are support for transactions with ACID semantics; sub-second queries; and SQL:2011 Analytics. The support for ACID transactions means you’ll be able to modify data with inserts, updates and deletes in the familiar way supported by standard SQL systems. The speed improvement in queries is aimed at making Hive usable for applications such as interactive dashboards and explorative analytics. To achieve this without losing scalability, the developers plan to use a hybrid engine based on Tez and something new called LLAP (Live Long and Process). LLAP is an optional daemon process running on multiple nodes, that provides caching and data reuse across queries with compressed columnar data in-memory (off-heap). It also supports multi-threaded execution including reads with predicate pushdown and hash joins. YARN will provide workload management in LLAP by using delegation. By limiting LLAP use to the initial phases of query processing, Hive sidesteps limitations around coordination, workload management and failure isolation. These are traditionally problems that are introduced by running the entire query within this process as done by other databases. The final major planned improvement is to add support for a subset of SQL:2011 Analytics. Further support will be added in the future as requested by customers. The constructs that will be supported in Stinger.next are non equi-joins; the set functions Union, Except and Intersect; interval types; and most sub-queries, whether nested or not.
More InformationRelated Articles
To be informed about new articles on I Programmer, install the I Programmer Toolbar, subscribe to the RSS feed, follow us on, Twitter, Facebook, Google+ or Linkedin, or sign up for our weekly newsletter.

Comments
or email your comment to: comments@i-programmer.info |
| Last Updated ( Monday, 08 September 2014 ) |