| Apache Beam Moves To Top Level |
| Written by Kay Ewbank | |||
| Tuesday, 07 February 2017 | |||
|
Apache Beam, a distributed processing tool with a unified programming model for both batch and streaming data processing, has achieved top level status as an Apache project.
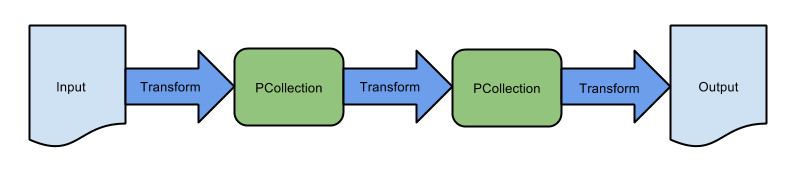
The name beam is a combination of Batch and strEAM. Beam aims to enable efficient execution across a number of distributed execution engines. It consists of a programming model, SDKs, and runners for defining and executing data processing pipelines. Apache Top Level Projects are the highest status in the Apache Foundation. Before achieving this status, a project has to go through an incubator period. Apache Beam was jointly proposed by Google, Talend, Cloudera, dataArtisans, PayPal and Slack as an Apache Incubator back in February 2016. Beam began life at Google, and is used as the Google Cloud Dataflow (GCD) service. Beam uses the same API as GCD. You can implement data processes using Beam via a Beam SDK. There are currently only two - Java and Python, with plans for a Scala SDK to be added in the future. Having chosen your SDK, you implement your data processes as Beam Pipelines. These are translated to the runtime where your processes will be deployed and run by Apache Beam runners.There are four runners available at the moment, for Apache Apex (aimed at Hadoop deployments), Apache Spark (Apache's main open source data processing engine), Apache Flink (a stream processing engine designed to be very memory efficient), and Google Cloud Dataflow. Plans are underway for runners for Apache Hadoop MapReduce, and Apache Karaf. A typical pipeline is shown below:
The advantages Beam offers are portability and unified processing. The portability comes from the decoupling of the data processing job and the runtime on which it will be executed. You can use the same code with a different runner and it will execute on the new backend without changes. The unified processing means you can use the same unified model for batch and stream processing. One interesting thing about Beam is how it offers a competitor to Spark. All the data processing engines supported by Beam are rivals for market share, and Spark is currently out in front because of the number of libraries and user acceptance. If Beam can provide a more engine agnostic approach, it could become the obvious choice when creating a data process to access big data.
More InformationRelated ArticlesFlink Gets Event-time Streaming Google Announces Big Data the Cloud Way
To be informed about new articles on I Programmer, sign up for our weekly newsletter, subscribe to the RSS feed and follow us on Twitter, Facebook or Linkedin.

Comments
or email your comment to: comments@i-programmer.info |