| Hiding data in disk fragmentation |
| Written by Mike James | |||
| Monday, 25 April 2011 | |||
|
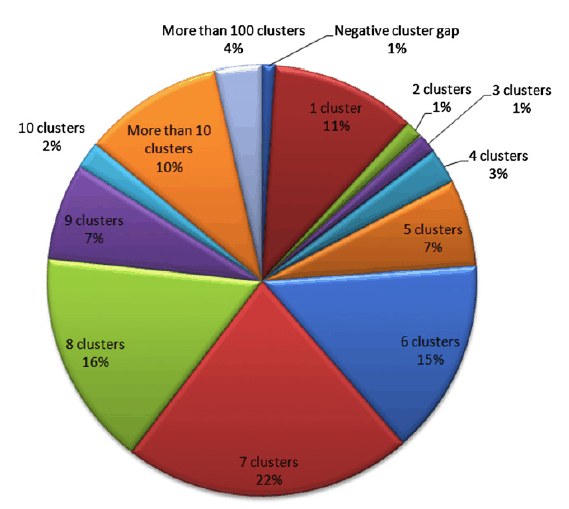
How do you keep something secret? A team of researchers has found a novel steganographic technique that uses the way data is stored on a hard disk. How do you keep something secret? If you encrypt it then the statistical properties of the stored data reveal that you have something to hide. Once the fact is out that you have something to hide then the process of revealing your secrets can begin. You could even be forced to reveal the encryption keys by law once it is known that you have encrypted data. An alternative is to hide you secrets in plain sight - a technique called steganography. For example you can store data as part of an image by changing a few pixels by an amount that isn't detectable. As long as you do the job correctly and don't give yourself away by modifying the statistics of the steganographic medium then it is fairly difficult to detect. The trick with steganography is to find something that you can use to hide the data without making it obvious. Now a team of researchers at University of Southern California in Los Angeles has found a novel steganographic technique, but not one without its problems. The idea is to use the way data is stored on a hard disk. Operating systems allocate blocks of storage to any file that you create. Exactly how they do this varies and, for the sake of argument, the example uses the FAT filing system that is now mostly superseded by NTFS under Windows but it is still used on small storage devices such as memory cards and USB sticks. FAT allocates storage in "clusters" and these can be spread out all over the disk. In most cases you really want any file to be stored in a set of physically adjacent clusters, but files can become fragmented and stored all over the drive. Normally this is considered a bad thing and disk defragmenters are used to tidy up a disk and make it more efficient. Some operating systems - Windows 7 for example - even perform defragmentation automatically. The steganographic system proposed simply uses the location of the clusters that make up a file to store the real data. There are lots of ways of hiding data in the cluster locations. For example, a simple coding rule is: if two storage blocks are physically next to each other then the next encoded bit is the same as the previous bit and if they are separated then the bit changes. This is a differential scheme that needs the first bit of the message to be specified and this is achieved by using the number of the starting cluster - odd is one and even is zero. So to code 110011 you would first allocate an odd numbered cluster to code the initial 1, then the block right next to it to code that the value of the bit hasn't changed, i.e. another 1. Then you would allocate a cluster well away from the first cluster to indicate that the data had changed from a 1 to a 0 and then a cluster physically next door to indicate no change, i.e. another 0, and so on. What happens if there isn't a cluster next door to the current cluster and you need to code that the bit doesn't change? The answer is that you can restart the code by making the next cluster even. So the code now depends on position and whether the cluster number is odd or even. You can see that once you have thought of the idea you can elaborate the algorithm to make it more flexible and harder to detect. For example, why not use the difference between clusters to code larger chunks of data. For example to store three bytes 8, 5, 3 you would store the a cluster at s, s+8, s+5 and s+3. The only problem is what happens if one of the clusters you want to use is already being used in a file? Easy just move it to a new location and use the cluster. The only time that this fails is if the file in question is already a steganographic file when you need to find an alternative collision resolution mechanism. The point is that you can work out the details of your own scheme - but there is one big problem. Any modification to the visible steganographic file will very likely erase the data hidden in its cluster locations. In short, if the disk is defragmented then the hidden data is lost. Even if you make sure that disk defragmentation doesn' occur there is the small problem that the coding method introduces additional fragmentation. To make it invisible to an investigator you have to hide the data in files that have similar fragmentation rates - the research paper details these ideas and explains how best to blend in. For example the pie chart below shows the typical spacing between clusters on a standard drive:
It all sounds like a lot of fun and as long as you can keep the defragmenter at bay it seems a very practical scheme to hide small amounts of data in plain sight. The researchers claim that the next step is to invent forensic methods that detect such steganographic coding. More InformationDesigning a cluster-based covert channel to evade disk investigation and forensics 
|
|||
| Last Updated ( Thursday, 28 April 2011 ) |