| Google Announces Big Data the Cloud Way |
| Written by Kay Ewbank | |||
| Wednesday, 22 April 2015 | |||
|
At the Hadoop Summit in Brussels, Google announced new cloud services and big data analytics tools.
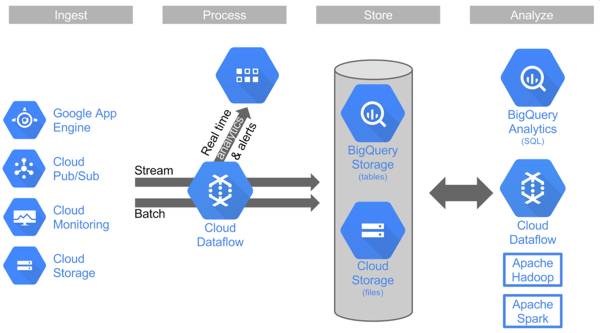
The range starts with the Cloud Dataflow tool for Big Data analytics, which until now has been in a private alpha program. Cloud Dataflow can be used for event-time-based stream processing. The same pipeline can execute in batch mode to keep costs down, or when analyzing historical data. Writing about the announcement on the Google Cloud Platform blog, Google’s William Vambenepe said that the release means that: “consistently processing streaming data at large scale doesn't have to be a complex and brittle endeavor that's reserved for the most critical scenarios." The service can be accessed by developers using an open source Java-based SDK. This can be used to run pipelines against the Cloud Dataflow service. Pipelines encapsulate an entire series of computations that accepts some input data from some external source, transform that data to provide some useful intelligence, and produce some output data. The processing patterns can be used in data processing scenarios such as session analysis, anomaly detection, and funnel analysis.
Alongside the new service, Google has added new features to Google BigQuery and has made it available in European zones. BigQuery is Google’s API-driven service for SQL analytics, and the new release has improved security and performance, such as row-level permissions to make data sharing more flexible. As well as the ability to analyze structured data, it has support for repeated records and querying inside JSON objects for loosely structured data. The final element of Google’s big data releases is a service called Google Cloud Pub/Sub that provides event delivery as a fully managed service. The blog post modestly says that: “Using big data the cloud way doesn’t mean that Hadoop, Spark, Flink and other open source tools originally created for on-premises can’t be used in the cloud. We’ve ensured that you can benefit from the richness of the open source big data ecosystem via native connectors to Google Cloud Storage and BigQuery along with an automated Hadoop/Spark cluster deployment.”
More Information
Related ArticlesGoogle Moves On From MapReduce, Launches Cloud Dataflow Major Update to Google BigQuery
To be informed about new articles on I Programmer, install the I Programmer Toolbar, subscribe to the RSS feed, follow us on, Twitter, Facebook, Google+ or Linkedin, or sign up for our weekly newsletter.

Comments
or email your comment to: comments@i-programmer.info |
|||
| Last Updated ( Wednesday, 22 April 2015 ) |