| Google Moves On From MapReduce, Launches Cloud Dataflow |
| Written by Kay Ewbank | |||
| Friday, 27 June 2014 | |||
|
Google has introduced a new cloud analytics system called Cloud Dataflow that is a successor to MapReduce. MapReduce has been a mainstay of Google’s data analytics for the last ten years, enabling them to process massive datasets using distributed computing - but now it is being replaced by something better.
Speaking at the I/O developer conference in San Francisco, Google’s Urs Hölzle, senior vice president of technical infrastructure said once the amount of data to be analyzed reached several petabytes, MapReduce became too cumbersome, saying in his keynote presentation, “We don’t really use MapReduce any more,” adding that Google stopped using MapReduce for analytics “years ago.” The reasons for Google dropping MapReduce, according to Hölzle, are that MapReduce makes it hard to ingest data rapidly. Analysis using it requires a lot of different technologies, batch and streaming are unrelated, and deployment and operation of MapReduce clusters is always required. Instead, Google now uses Google Cloud Dataflow. According to the Google Cloud Platform blog, this is: “a fully managed service for creating data pipelines that ingest, transform and analyze data in both batch and streaming modes. Cloud Dataflow is a successor to MapReduce, and is based on our internal technologies like Flume and MillWheel.” Flume lets Google more easily build complex data pipelines that handle the entire process of acquiring, cleaning, and analyzing batch data. In Cloud Dataflow, Flume has been combined with MillWheel, which internally is used for stream processing, analyzing data in near real-time as it comes into Google.
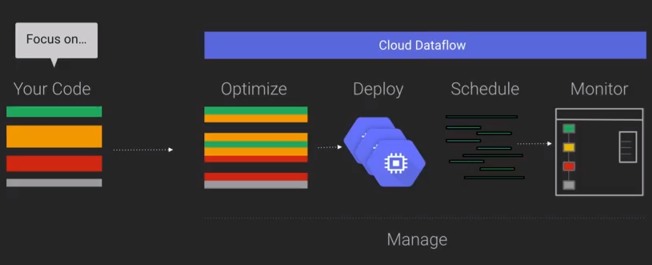
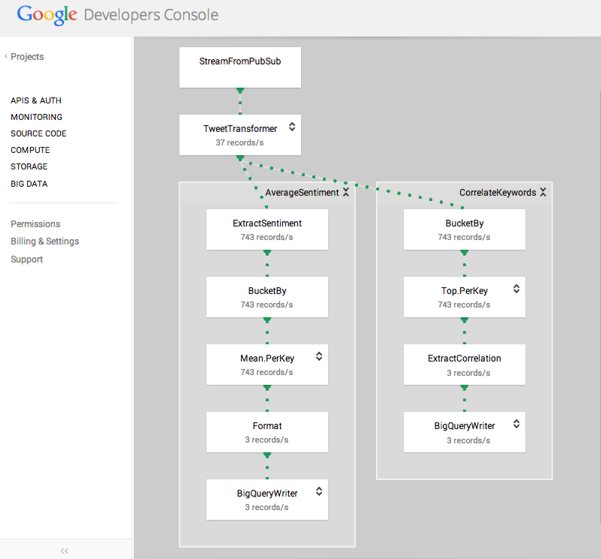
Cloud Dataflow will let you build and optimize data pipelines, create mobile applications, and debug, trace, and monitor your cloud apps in production. Cloud Dataflow can be used for tasks such as ETL (Extract Transform Load), batch data processing and streaming analytics, and it will automatically optimize, deploy and manage the code and resources required. Hölzle said in his keynote that “Cloud DataFlow is the result of over a decade of experience in data analytics.” He added that “It will run faster and scale better than pretty much any other system out there.” Demos during the keynote included analysis of tweets posted about World Cup soccer matches. Other tools in the range were also announced at the conference. Google Cloud Trace can be used to find performance bottlenecks. It is based on the concepts of DTrace, (originally developed by Sun Microsystems), but has been developed entirely at Google. Cloud Save is an API that means your apps can save a user’s data in the cloud and use it without needing any server-side coding. Data is stored in Google Cloud Datastore, making the data accessible from Google App Engine or Google Compute Engine using the existing Datastore API. Google Cloud Save is currently in private beta and will be available for general use soon. Cloud Debugging, Tracing and Monitoring apps were all also introduced. Cloud Tracing provides latency statistics and analysis reports across different groups, while Cloud Monitoring is an intelligent monitoring system that does use features from Stackdriver, the cloud monitoring service that Google acquired a few months ago.
You can monitor cloud infrastructure resources, such as disks and virtual machines, as well as service levels for Google’s services. The blog post says: “Cloud Monitoring provides rich metrics, dashboards and alerting for Cloud Platform, as well as more than a dozen popular open source apps, including Apache, Nginx, MongoDB, MySQL, Tomcat, IIS, Redis, Elasticsearch and more. For example, you can use Cloud Monitoring to identify and troubleshoot cases where users are experiencing increased error rates connecting from an App Engine module or slow query times from a Cassandra database with minimal configuration.” Cloud Debugger gives you a full stack trace and snapshots of all local variables for any watchpoint that you set in your code while your application continues to run undisturbed in production. Here is the full keynote from Google I/O, which lasts for two and a half hours. Urs Hölzle's presentation starts at 1:55:38 and his announcement of Cloud Dataflow comes at 2:08:24.
More InformationSneak peek: Google Cloud Dataflow, a Cloud-native data processing service Related ArticlesElastic MapReduce Demo Shows How to Handle Large Datasets Intel Announces Beta Data Platform Most Businesses Moving To Big Data
To be informed about new articles on I Programmer, install the I Programmer Toolbar, subscribe to the RSS feed, follow us on, Twitter, Facebook, Google+ or Linkedin, or sign up for our weekly newsletter.

Comments
or email your comment to: comments@i-programmer.info |
|||
| Last Updated ( Friday, 27 June 2014 ) |