| Open Source Better Than Proprietary Code |
| Written by Alex Armstrong |
| Monday, 21 April 2014 |
|
On the basis of scanning million of lines of code Coverity has discovered that in 2013, the defect density in open source code was lower than that in proprietary code. This may be less than reassuring given the ongoing Heartbleed threat. The Coverity Scan service, which was originally initiated in 2006 , with the U.S. Department of Homeland Security, enables open source developers to test their Java, C and C++ code as it is written, flag defects and provide them with information needed to fis them. Last year's Coverity Scan 2012 report revealed that Open Source has as good code quality as proprietary code with proprietary code having an average defect density of 0.68 compared to 0.69 for open source code. Tht finding was based on analysis of more than 450 million lines of software code from 118 projects Over the past year the number of projects using the service has greatly increased so that Coverity Scan now has more than 1500 projects.
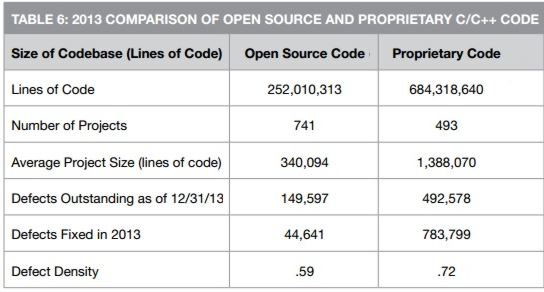
In its analysis of C/C++ code, the 2013 report covered over 250 million lines of open source code from 741 of the most active C/C++ projects, as well as almost 700 million lines of code from an anonymous sample of nearly 300 of Coverity’s customers. In terms of defect density, i.e. the defects outstanding at the end of the year, for the first time, open source code quality has surpassed proprietary C/C++ code quality, with a rate of 0.59 (as opposed to 0.72) per 1,000 lines of code. Look at the the total number of defects found (i.e. those fixed as well as those outstanding) shows that proprietary code has a defect rate of 1.87 defects per 1,000 lines compared to only compared to only 0.77 for open source code but proprietary projects are much more likely to fix defects. Over 60% of proprietary code defects were fixed compared to less than a quarter of open source ones. Since May 2013 Coverity Scan has included support for Java and has attracted more than 100 open source projects including Big Data projects such as Apache Hadoop, Apache HBase and Apache Cassandra. With regard to the differences between Java and C/C++ code the report states: Overall defect density in Java projects was 2.72, which is significantly higher than the .59 defect density of C/ C++ projects in 2013. There are several factors that impact the density level. First, the analysis algorithms for Java and C/C++ differ. The analysis we provide for the Scan service includes the popular FindBugs checkers, which are very useful. Many of the FindBugs checkers generate large quantities of results, in particular in the areas of dodgy code, performance and bad practices. Another factor to consider when assessing the defect density of the Java programs is the length of time the Scan service has been available to the projects. It is not uncommon to see higher defect density rates in the early stages of a project’s participation in the service, followed by a reduction in the defect density over time.
The report single out HBase as a benchmark for Java quality stating: Coverity has helped HBase (the Hadoop database) fix more than 220 defects, including a much higher percentage of high-impact defects than other Java projects (66% for HBase vs. 13% for all other Java projects).
At the same time as publishing the 2013 report Coverity announced today that it has opened up access to the Coverity Scan service, allowing anyone interested in open source software to view the progress of participating projects as Project Observers. This status enables indiciduals to view high-level data including the count of outstanding defects, fixed defects and defect density. Zach Samocha, senior director of products for Coverity, explained with initiative: “We’ve seen an exponential increase in the number of people who have asked to join the Coverity Scan service, simply to monitor the defects being found and fixed. In many cases, these people work for large enterprise organizations that utilize open source software within their commercial projects. By opening up the Scan service to these individuals, we are now enabling a new level of visibility into the code quality of the open source projects, which they are including in their software supply chain.” More Information2013 Coverity Scan Open Source Report (pdf)
Related ArticlesOpen Source Has As Good Code Quality As Proprietary Code HeartBleed - The Programmers View The True Cost Of Bugs - Bitcoin Errors GOTCHA - No More Password Hacking Stick Figure Guide To AES Encryption Android Security Hole More Stupid Error Than Defect Smartphone Apps Track Users Even When Off
To be informed about new articles on I Programmer, install the I Programmer Toolbar, subscribe to the RSS feed, follow us on, Twitter, Facebook, Google+ or Linkedin, or sign up for our weekly newsletter.

Comments
or email your comment to: comments@i-programmer.info |
| Last Updated ( Tuesday, 27 May 2014 ) |