The edit distance between two strings is simply how many primitive edit operations are needed to change one string into another. Easy to state but very difficult to compute and its an important algorithm that is used in everything from spelling checkers to genetic analysis. In many cases we can get by with an approximation that is easier to compute but how good are they?
The edit distance is a basic string similarity measure used in many applications such as text mining, signal processing, bioinformatics, and so on. However, the computational cost can be a problem when we repeat many distance calculations as seen in real-life searching situations.
A promising solution to cope with the problem is to approximate the edit distance by another distance with a lower computational cost. There are, indeed, many distances have been proposed for approximating the edit distance. However, their approximation accuracies are evaluated only theoretically: many of them are evaluated only with big-oh (asymptotic) notations, and without experimental analysis. Therefore, it is beneficial to know their actual performance in real applications.
In this study we compared existing six approximation distances in two approaches:
(i) we refined their theoretical approximation accuracy by calculating up to the constant coefficients,
and
(ii) we conducted some experiments, in one artificial and two real-life data sets, to reveal under which situations they perform best.
As a result we obtained the following results: [Batu 2006] is the best theoretically and [Andoni 2010] experimentally. Theoretical considerations show that [Batu 2006] is the best if the string length n is large enough (n >= 300). [Andoni 2010] is experimentally the best for most data sets and theoretically the second best. [Bar-Yossef 2004], [Charikar 2006] and [Sokolov 2007], despite their middle-level theoretical performance, are experimentally as good as [Andoni 2010] for pairs of strings with large alphabet size.
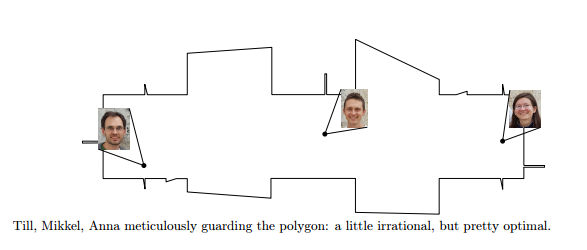
The art gallery problem is fun and in this case the guards being irrational doesn't quite mean what you think - is this clickbait? Probably, but it's very upmarket clickbait.
In this paper we study the art gallery problem, which is one of the fundamental problems in computational geometry.
The objective is to place a minimum number of guards inside a simple polygon such that the guards together can see the whole polygon. We say that a guard at position x sees a point y if the line segment xy is fully contained in the polygon.
Despite an extensive study of the art gallery problem, it remained an open question whether there are polygons given by integer coordinates that require guard positions with irrational coordinates in any optimal solution.
We give a positive answer to this question by constructing a monotone polygon with integer coordinates that can be guarded by three guards only when we allow to place the guards at points with irrational coordinates. Otherwise, four guards are needed.
By extending this example, we show that for every n, there is polygon which can be guarded by 3n guards with irrational coordinates but need 4nguards if the coordinates have to be rational. Subsequently, we show that there are rectilinear polygons given by integer coordinates that require guards with irrational coordinates in any optimal solution.
The Discrete Cosine Transformation DCT is the approximation to the Fourier transform used in most digital signal processing and being able to compute it quickly is important. For example the 8-point DCT is used in JPEG compression. Now we have an approximation to the matrix transform that can be performed in just 14 additions:
A low-complexity 8-point orthogonal approximate DCT is introduced. The proposed transform requires no multiplications or bit-shift operations. The derived fast algorithm requires only 14 additions, less than any existing DCT approximation. Moreover, in several image compression scenarios, the proposed transform could outperform the well-known signed DCT, as well as state-of-the-art algorithms.
Akka has launched a new Akka Agentic Platform that can be used to build, operate, and evaluate any type of agentic AI system. The platform provides orchestration, memory, toolkits for agents, and [ ... ]
Generative AI is having an revolutionary impact across the board. Some jobs will be lost but more will be created and to get in on the ground floor now is the time to gain a credentials to show employ [ ... ]