| Game-powered Machine Learning Finds the Music |
| Written by Mike James | |||
| Thursday, 10 May 2012 | |||
|
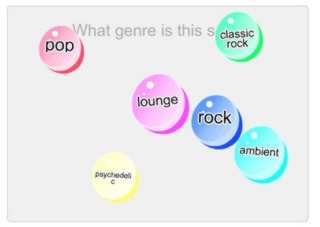
Machine learning is all the rage at the moment, but it is still just as difficult to find the data you need to perform the training. Game-powered machine learning is one way around the problem - in some situations at least. As Google, with translation, and Microsoft, with body tracking, have proved, making machine learning techniques perform real world tasks can be a matter of having enough data. As the amount of data you have a available for training goes up, the actual machine learning algorithm that you are using matters less. Basically, if the task can be made easy to learn then anything will do well at learning it. There is a lot of data on the web and this is why machine learning and "big data" have tended to rise together. Unfortunately, most of the available data is "unlabeled" and for supervised training you need labeled data. For example, suppose you want to classify music into different genres, then you have no problem at all finding unlabeled or poorly labeled samples. What you really need are lots of music tracks that have been carefully categorized and this is generally expensive. As a result training sets tend to be small.
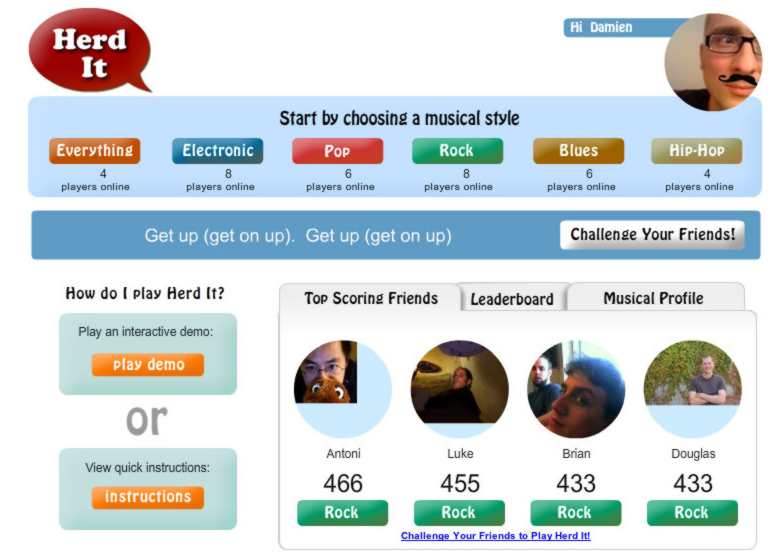
A team at UCSD Jacobs School of Engineering has come up with an idea that might solve lots of similar problems - turn the labeling task into a game. Its Herd It game on Facebook uses people enjoying themselves to label music samples. Of course, the users don't think that they are helping with an AI training task; as far as they are concerned they are testing their knowledge of music trivia. They can challenge friends and there's a leaderboard. The labeled data can then be used to train a machine learning system how to recognize features of the audio spectrum. So far things seem nothing more than a gamification of a labeling task - but there is clever twist. The outcome of the machine learning algorithm can be used to modify the game to provide categories that help subdivide the musical universe more accurately. In a way this is like the machine learning algorithm asking for more input and creating a game to ensure that it gets just what it needs to perform better.
The eventual objective is to accurately tag new music, i.e. music that is outside of the training set, so that users can perform searches for music that they might like. Given that a music service like Pandora already has 900,000 songs, the advantage of an automatic accurate classification is obvious. The researchers speculate that one day the technique could be used to provide a personal radio station that finds new music that you have a high probability of liking and even tailor what you are listening to according to the time of day and other factors.
While a music search engine is a worthwhile objective, it is clear that Game-powered machine learning could have applications in other areas. All you have to do is work out how to gamify the classification task and then find a way to feed back the performance for the machine learning to modify the game. More InformationRelated ArticlesHow the Music Flows from Place to Place A Dozen Free Online Computer Science Courses A First Course in Machine Learning
Comments
or email your comment to: comments@i-programmer.info To be informed about new articles on I Programmer, subscribe to the RSS feed, follow us on Google+, Twitter, Linkedin or Facebook or sign up for our weekly newsletter. 
|
|||
| Last Updated ( Friday, 11 May 2012 ) |