| UPDATE - Data Science Predicts Oscar Winner Correctly |
| Written by Lucy Black | |||
| Monday, 05 March 2018 | |||
|
This weekend sees the 90th Academy Awards, causing anticipation and tension - there's a lot riding on the Best Picture Award, not only in Hollywood but also across America and around the globe. Thinkful decided to use the power of data science to pick the winner .... and now we know its prediction of The Shape of Water turned out to be the right one.
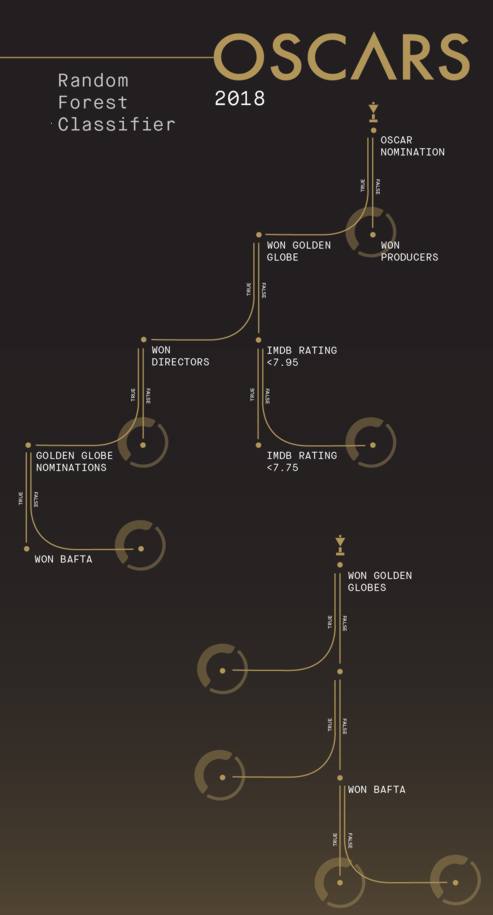
The team at online coding bootcamp, Thinkful, used supervised learning to look for patterns in past outcomes to predict future ones - i.e. this year's. In his blog post Adam Levenson writes: We began our journey to predicting this year’s best picture winner by collecting and cleaning lots of data. From critic ratings to performance at precursors, we looked for any and all publicly available information about the films that had been nominated for Best Picture over the past X years. This data would help inform our algorithm which we would build using SciKit Learn, one of the most popular learning toolkits in the world. SciKit Learn is an open source toolk for machine learning in Python build on NumPy, SciPy and matplotlib. Levenson continues: Through evaluating multiple models, we determined that random forest classification provided the most accurate prediction of previous Oscar winners. Random forest classification is a machine learning method that determines the relationships between variables through the creation and evaluation of decision trees. While not particularly trendy as a machine learning approach, random forest classification has stood the test of time and we've reported it being used for earthquake prediction, identifying drivers from how they take a corner and even de-anonymizing C++ programmers from their code once compiled to executable binaries. The following decision trees applying a series of Yes/No questions to the nine nominations for Best Picture were used for the Oscars 2018 prediction:
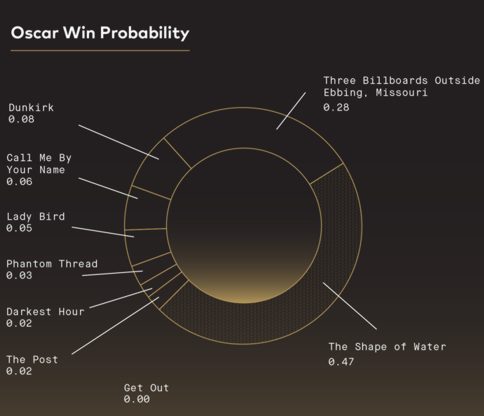
According to Levenson: The Random forest classifier algorithm recognizes that as decision trees become more complex, they have a tendency to pick up on nuance and creates rules on randomness in a process known as capturing noise or overfitting. Therefore, rather than creating large complex trees, random forest makes many small trees with slight variations, allowing us to find higher level, generalizable rules. When applied to Oscar winners and losers over the past 38 years, this approach made correct predictions in all but 1 year, 2017. As they say, if you don't want to know the answer look away now. Otherwise consult the chart for the movie that is clearly in the lead with a win probablilty of 0.47. The nearest contender has a win probability of 0.28, while the outfield comprises one at each of 0.08, 0.06, 0.05 and 0.03; two at 0.02 and one at 0.00 - which raises the question how did that movie ever get to be nominated!
We'll have to wait until tomorrow to see if Thinkful 's prediction was the right one - and I for one will pay a little more attention when the fateful envelope is opened.
More InformationAnd the Oscar goes to data science Related ArticlesGet On The Machine Learning Bandwagon With Google Earthquake Prediction Using Machine Learning I Know Who You Are By The Way You Take A Corner Identifying Programmers From Executable Binaries
To be informed about new articles on I Programmer, sign up for our weekly newsletter, subscribe to the RSS feed and follow us on Twitter, Facebook or Linkedin. 
Comments
or email your comment to: comments@i-programmer.info
|
|||
| Last Updated ( Monday, 05 March 2018 ) |