| Google's Teachable Machine - What it really signifies |
| Written by Nikos Vaggalis | |||
| Wednesday, 18 October 2017 | |||
|
The Teachable Machine is an effort by Google to make Machine Learning and AI accessible to the wider public, without requiring any specialized training, knowledge in Computer Science or coding.
The site https://teachablemachine.withgoogle.com/ is a move that reflects the current trend of the personalization of AI in shifting the algorithms from the Cloud to the user's space, be it their desktop, their phone or other smart device. That's not the biggest problem though; the real issue is that the models used for training the algorithms under the common supervised learning model, require massive datasets and excessive amounts of CPU power. So as the situation currently stands, the bulk processing is done on the Cloud by Platform as a Services which offer Machine Learning as plug and play API's which encapsulate the necessary pre-trained algorithms, with offerings including tone analysis, visual recognition or conversation analysis. Prevalent examples of such PaaS are Haven OnDemand and IBM's Watson/BlueMix. But the tide seems to turning. Back in August 2016, in AI Linux, we identified a divergence to this trend: Things seem to be shifting though, with those elaborate algorithms looking to move on to run locally on mobile devices. That includes their training too; the pictures, notes, data and metadata that reside in the device and which are going to be worked upon, will also serve to train the network and aid its learning activities such as the recognizing, ranking and classifying of objects. The difference is that now all of that is going to happen locally. Qualcomm's Snapdragon 820 processors and their accompanying Snapdragon Neural Processing Engine SDK are behind such a move which would allow manufactures to run their own neural network models on Snapdragon powered devices, such as smart phones, security cameras, automobiles and drones, all without a connection to the cloud. Common deep learning user experiences that could be realized with the SDK, would be scene detection, text recognition, object tracking and avoidance, gesturing, face recognition and natural language processing. So instead of the ML algorithms being bred on the cloud, satisfying their hunger with user-collected data, the alternative idea is to shift both the algorithms as well their training offline and onto the source generating the data in the first place. Since then, such attempts have been intensified, now focusing on the browser, and quite reasonably so as it is the single most pervasive and ubiquitous piece of software ever made. So why not utilize the same power in training ML algorithms as well? At least until the holy grail of AI, that of unsupervised learning, really takes off...See OpenAI Universe - New Way of Training AIs This kind of approach has multiple advantages: Cloud processing requires the presence of either a WiFi or mobile connection, which can be sluggish as well as posing a host of privacy concerns. Then, looking at it from a practical perspective, multiple concurrent requests from thousands of client devices can easily overload the cloud based service and leave the client machine prone to long delays in getting a response, or even to fully scaled denials of service. Privacy concerns also are obvious. We solely rely on Terms of Service and Privacy Policies, like those related to Face Recognition as posed by the Quebec Musée de la Civilisation in "Find Your 2000-Year-Old Double With Face Recognition", where the Museum promises:
or Bitesnap's in "Applying Deep Learning to Calorie Counting" :
Let me emphasize that both the Museum as well Bitesnap are used here as indicative samples of the most common practices used in handling user submitted data, and not as examples of wrongdoing.On the contrary we are confident that those services keep their word and believe in their commitment to keep personal data safe. But the point is, why rely on promises when we could be keeping all data of ourselves to ourselves?
Google's Teachable Machine then, is a prime demonstration of that notion. While it requires the use of your camera to take stills of yourself to train its models, all your data stays inside your browser. This happens due to Javascript and the deeplearn.js library, the work horse behind the application that gets loaded inside your browser and uses its local storage capabilities so that everything is performed and kept solely on the client side. Apart from being a clever promotional tool, the Teachable Machine has substantial value in setting the necessary pre-conditions for the next level in the era of AI to commence, treating it as commodity consumable by end users. Offloading pre-trained algorithms to the consumer's device is one thing, but teaching the public how to train, customize and tweak them according to one's need is a totally different story. It goes without saying that teaching users to write code in order to train their algorithms is neither feasible nor end-user-friendly. What could be done instead? just watch the following "Objectifier-Spacial Programming" video in order to get a glimpse at the future of algorithm customization. This includes teaching the algorithm to :
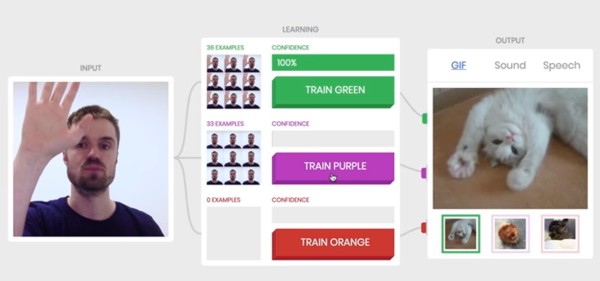
While training a Neural Network inside the browser is not Google's innovation, since libraries the likes of ConvNet.js predate Google's efforts, the difference is in the commitment. Whereas ConvNet.js is the brain child of just a single individual, Andrej Karpathy who was previously a Research Scientist at OpenAI and CS PhD student at Stanford and is now Director of AI at Tesla, deeplearn.js has the full backing of Google's People+AI Research Initiative (PAIR). This should guarantee its continuous and systematic development. In order to train a Neural Network using the Teachable Machine you simply have to turn on your web camera, press and hold down a button and while the button remains depressed, perform a repetitive move in front of the lens of the camera. That's all there is to it.
There are three buttons, green, purple and orange, each assigned to a separate NN, so that you can bind each one of them to a distinct action. After training the NNs, the next time you perform your moves, the NNs are going to try recognize and classify them in order to perform the user defined actions. The predefined ones play gifs of cats (what else?), sounds or speech samples, but they can be easily changed by the end user. This is something that leads to people using the machine in pretty imaginative and fun ways, as the following videos demonstrate.
Of course the applications are countless and not just funny like training a convolutional neural network to recognize photos and handwritten digits all in your browser without writing a single line of code.
More InformationPAIR | People+AI Research Initiative Related ArticlesIBM Watson and Project Intu for Embodied Cognition IBM, Slack, Watson and the Era of Cognitive Computing OpenAI Universe - New Way of Training AIs Find Your 2000-Year-Old Double With Face Recognition Applying Deep Learning to Calorie Counting ConvNetJS: Deep Learning in your browser
To be informed about new articles on I Programmer, sign up for our weekly newsletter, subscribe to the RSS feed and follow us on Twitter, Facebook or Linkedin. 
Comments
or email your comment to: comments@i-programmer.info
|
|||
| Last Updated ( Wednesday, 18 October 2017 ) |