| Learning To Walk |
| Written by Mike James | |||
| Wednesday, 12 July 2017 | |||
|
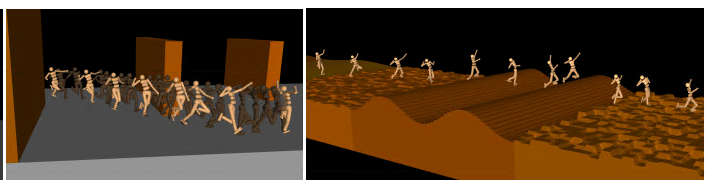
Deep Mind has been applying its deep reinforcement learning to the problem of walking - but not just any walking, this is difficult terrain. The neural network gets it wrong some of the time, but it is still impressive and its fails are fun to watch.
If you have ever watched a robot walk, you will wonder why the task is so hard. It is hard, but neural networks solve some very hard problems and it is surprising that robot walking isn't much better than it is. The Deep Mind team clearly think that its reinforcment learning approach is the way to go, and from the video this seems to be correct:
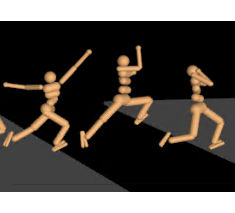
The paper that accompanies the video describes the approach in detail. In particular, it explains that the big problem with this sort of dynamical problem is crafting the reward function. In the past when complex reward functions have been used to shape behavior, the result has been largely unsuccessful. The robots learned to walk but did unexpected things and small changes to the reward function produced big changes in behaviour. The Deep Mind team used a simple reward function arguing that complex reward function are a form of overfitting that results in idiosyncratic solutions that happen to work in one setting. They also argue that a simple reward function used to train on as wide a variety of obstacle courses will promote more generalized behaviour. The agents used in the training had a range of feedbacks: (1) a set of egocentric, “proprioceptive” features containing joint angles and angular velocities; for the Quadruped and Humanoid these features also contain the readings of a velocimeter, accelerometer, and a gyroscope positioned at the torso providing egocentric velocity and acceleration information, plus contact sensors attached to the feet and legs. The Humanoid also has torque sensors in the joints of the lower limbs. (2) a set of “exteroceptive” features containing task-relevant information including the position with respect to the center of the track as well as the profile of the terrain ahead. Watching the humanoid is really interesting. If you have seen similar experiments involving the evolution of locomotion via walking the results may look superficially similar, but the way the arms move in the neural network case seems much more determined. While the arms appear to flail about like a demented lunatic, if you look carefully they do seem to be used as a counter balance and as momentum generators. To produce motion that is more acceptable to human onlookers the reward function should probably be modified to include a cost for not having the arms close to their rest position.
Overall though, the idea of a simple reward function and complex environment seems to work. The conclusion is: "Our experiments suggest that training on diverse terrain can indeed lead to the development of non-trivial locomotion skills such as jumping, crouching, and turning for which designing a sensible reward is not easy. While we do not claim that environmental variations will be sufficient, we believe that training agents in richer environments and on a broader spectrum of tasks than is commonly done today is likely to improve the quality and robustness of the learned behaviors – and also the ease with which they can be learned. In that sense, choosing a seemingly more complex environment may actually make learning easier." This is most likely a very general result.
More InformationEmergence of Locomotion Behaviours in Rich Environments Nicolas Heess, Dhruva TB, Srinivasan Sriram, Jay Lemmon, Josh Merel, Greg Wayne, Yuval Tassa, Tom Erez, Ziyu Wang, S. M. Ali Eslami, Martin Riedmiller, David Silver Related ArticlesEvolution Is Better Than Backprop? The Virtual Evolution Of Walking To be informed about new articles on I Programmer, sign up for our weekly newsletter, subscribe to the RSS feed and follow us on Twitter, Facebook or Linkedin. 
Comments
or email your comment to: comments@i-programmer.info |
|||
| Last Updated ( Wednesday, 12 July 2017 ) |