| Self Driving Cars Can Be Easily Made To Not See Pedestrians |
| Written by Mike James | |||
| Wednesday, 03 May 2017 | |||
|
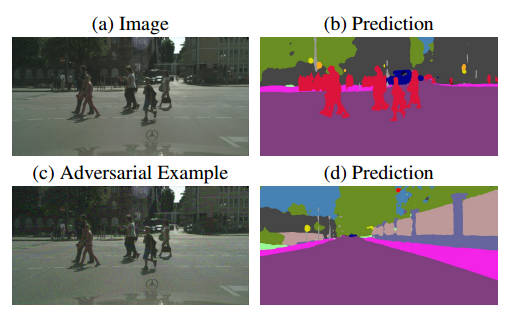
This is another chapter in the ongoing and long-running story of universal adversarial perturbations. In this case the technique has been extended to image segmentation and the perturbations can make pedestrians invisible to a neural network and yet appear unaltered to human vision. First off I need to say that the whole "self driving car" angle is slightly spurious, but the research has been done by Jan Hendrik Metzen and Volker Fischer of the Bosch Center for AI and Thomas Brox and Mummadi Chaithanya Kumar of the University of Freiburg so there is a car connection. The paper reporting the results also uses pedestrian removal as an example. It is slightly spurious, however, because at the moment at least most self driving cars don't use neural networks connected to a video camera. Instead they rely on an array of sensors, signal processing and decision algorithms. There are examples of cars that are neural network-based, but at the moment these are some way off being safe enough to trust. The problem is how can you know what a neural network is going to do when you don't really understand how it works? Adversarial perturbations are not new but they are still surprising. Take an image that a neural network classifies correctly and add a small change across the pixels, so small that a human cannot see it, and the neural network will misclassify the image. As far as a human is concerned, the original and the tampered with image look very similar, if not identical, and yet one the network gets right and the other is just silly. This is a surprise, but what is more surprising is that there exists a set of universal perturbations that will do the job. That is, you don't need to engineer a disruptive image to add to the correctly classified image, there are many images that will do the job for all correctly classified images. What is new about this research is that the idea has been extended from classification to segmentation. This isn't surprising in that segmentation is related to classification. Segmentation is where pixels that belong to an object are classified correctly. So, for example, segmentation is used to find and track the location of pedestrians or any object of interest in a video feed. It is worth saying that neural networks are not the only approach to segmentation and there are many successful object tracking methods that aren't based on neural networks. As you might guess if you have been following the story, it is very possible to construct universal perturbations that can remove a given category of object from the segmentation. This makes it sound almost obvious, but if you look at an example it is no less disturbing:
You can see that the original image (a) and the modified image (c) look similar but where did the pedestrians go? What is more, the same adversarial image added to any video frame makes the neural network blind to pedestrians. The paper states: • We show the existence of universal adversarial perturbations for semantic image segmentation models on the Cityscapes dataset • We propose two efficient methods for generating these universal perturbations. These methods optimize the perturbations on a training set. The objective of the first methods is to let the network yield a fixed target segmentation as output. The second method’s objective is to leave the segmentation unchanged except for removing a designated target class. • We show empirically that the generated perturbations are generalizable: they fool unseen validation images with high probability. Controlling the capacity of universal perturbations is important for achieving this generalization from small training sets. • We show that universal perturbations generated for a fixed target segmentation have a local structure that resembles the target scene The conclusion points out: Moreover, an adversary can blend out certain classes (like pedestrians) almost completely while leaving the rest of the class map nearly unchanged. Which means that not only are the perturbations not noticeable but apart from the missing class, i.e. the pedestrians, the other classes are mostly unaffected. So, for example, you could craft a perturbation that made a car not see pedestrians while still managing to see and avoid other cars. Is this a big problem for self driving cars and similar safety critical systems? Not really. The attacker would have to inject the adversarial perturbation directly into the car's video feed and this would mean physically breaking into the car. If a way to remotely influence the video feed via an internet of vehicles then the exploit would be very real. As I have commented before, I am surprised that the AI neural network community seems to be so focused on the security aspect of adversarial perturbations. Yes is it shocking that a video feed can be doctored to remove pedestrians without any obvious tampering, but it is much more interesting to ask what is it about neural networks that makes this possible? The addition of noise with a structure that makes it not typical of a natural image can understandably make a neural network get things wrong, but how can we train networks to ignore such artificial patterning?
More InformationUniversal Adversarial Perturbations Against Semantic Image Segmentation Related ArticlesDetecting When A Neural Network Is Being Fooled Neural Networks Have A Universal Flaw The Flaw In Every Neural Network Just Got A Little Worse The Deep Flaw In All Neural Networks The Flaw Lurking In Every Deep Neural Net Neural Networks Describe What They See Neural Turing Machines Learn Their Algorithms To be informed about new articles on I Programmer, sign up for our weekly newsletter, subscribe to the RSS feed and follow us on Facebook or Linkedin. 
Comments
or email your comment to: comments@i-programmer.info
|
|||
| Last Updated ( Wednesday, 03 May 2017 ) |