| Evolution Is Better Than Backprop? |
| Written by Mike James | |||
| Wednesday, 05 April 2017 | |||
|
Yes, another neural network breakthrough. This one provides us with a way of training using reinforcement learning, but without the need for the biologically implausible and expensive back propagation method. The latest work from Open AI is quite a shock, or perhaps not if you have been a supporter of the genetic algorithm approach to AI. It comes from a team which includes OpenAI’s research director and ex-student of Geoffrey Hinton, Ilya Sutskever. Currently the reinforcement approach to neural networks takes a neural network and uses back propagation (backprop) to move the network's parameters in a direction that maximizes the reward it receives. The changes in the network's parameters are computed using the gradient of the network to back-propagate the corrections needed to make the network's output move towards increasing reward. A typical network might have 1,000,000 parameters or more and so the whole operation is very computationally expensive. There are also other problems with back-propagation. If you worry about such thing, it is biologically implausible. If neural networks are supposed to be analogs of biological neural networks then this analogy breaks down, or is at best very strained, if you use backprop because biological networks don't compute exact gradients and perform anything that is explicitly back propagation. There are also practical difficulties in applying backprop. Often the gradients become very close to zero and this makes learning very, very slow. On the plus side, reinforcement learning neural networks have been spectacularly successful recently with Google's Deep Mind mastering a range of computer games and beating leading human players of Go at their own game. In short backprop is at the heart of the huge successes that we have been having recently in AI. It may not have the center stage all to itself for much longer. The new algorithm - evolution strategies or ES - is much closer to what might be happening in the biology, although it would be a mistake to identify it with the operation of evolution in the natural world. It is an optimization algorithm that works by selecting, say, 100 random directions in the parameter space "close" to the current parameter vector. This provides 100 candidate parameter vectors which can be evaluated. Then the 100 parameter vectors are combined by a weighted average with the weights being proportional to the reward each vector received. You can see that is likely to move the network in the direction of doing better.
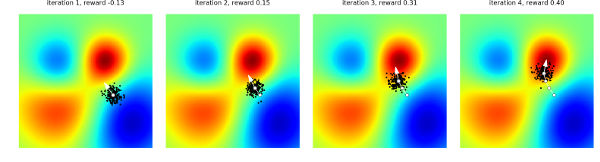
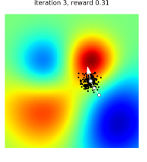
In two dimensions the way ES works is almost obvious - taking so many samples makes it almost certain you are going to find a direction that moves you to the higher reward - the red area. If you can imagine this process, then intuition probably leads you to believe convergence would be incredibly slow - close to undetectable in reasonable computation. What is surprising is that it works and works very efficiently. Since ES requires negligible communication between workers, we were able to solve one of the hardest MuJoCo tasks (a 3D humanoid) using 1,440 CPUs across 80 machines in only 10 minutes. As a comparison, in a typical setting 32 A3C workers on one machine would solve this task in about 10 hours. Other examples are given where ES provides comparable performance to backprop but using less computation. By using hundreds to thousands of parallel workers, ES can solve 3D humanoid walking in 10 minutes and obtain competitive results on most Atari games after one hour of training time. ES could well bring large scale neural networks within the reach of smaller and less well funded groups but there are a few points worth noting. The most important is that ES is only effective in reinforcement learning. In supervised learning, where the a trainer provides the correct target and where it is possible to compute an exact error, backprop is much faster than ES: For example, in our preliminary experiments we found that using ES to estimate the gradient on the MNIST digit recognition task can be as much as 1,000 times slower than using backpropagation. It is only in RL settings, where one has to estimate the gradient of the expected reward by sampling, where ES becomes competitive. In the bigger picture, however, supervised learning is a much more specialized technique - more like statistics than AI. After all, how often do you have a perfect teacher in the real world. In the real world learning is by reinforcement not supervision. It is also worth noting that this isn't the genetic algorithm applied to neural networks. It is more like a form of stochastic optimization. To be an example of the genetic algorithm, the parameter vector would have to be regarded as an artificial genome and be subjected to crossover and mutation. The algorithm would also keep a population of vectors between each generation, in the hope of breeding some fitter vectors. In the case of the ES algorithm, there is no crossover or mutation, just 100 random directions and the these are blended together according to their fitness, rather than only high fitness examples surviving. What is really interesting is that with 1,000,000 parameters you are working in 1,000,000-dimensional space. Choosing 100 random directions doesn't seem to be enough to explore to get the system to move to an optimum. However. repeating for 10,000 iterations does give a good chance of exploring a good number of possible directions. It is fairly obvious that this is some sort of randomized finite difference method. The actual nature of the algorithm doesn't really matter. What matters is that this is a fast way of training networks using a reinforcement signal alone.
More InformationEvolution Strategies as a Scalable Alternative to Reinforcement Learning Evolution Strategies as a Scalable Alternative to Reinforcement Learning - Paper Related ArticlesA Single Perturbation Can Fool Deep Learning OpenAI Gym Gives Reinforcement Learning A Work Out AI Goes Open Source To The Tune Of $1 Billion AlphaGo Revealed As Mystery Player On Winning Streak World Champion Go Player Challenges AlphaGo AlphaGo Beats Lee Sedol Final Score 4-1 Why AlphaGo Changes Everything Google's AI Beats Human Professional Player At Go Google's DeepMind Learns To Play Arcade Games Microsoft Wins ImageNet Using Extremely Deep Neural Networks
To be informed about new articles on I Programmer, sign up for our weekly newsletter, subscribe to the RSS feed and follow us on Twitter, Facebook or Linkedin. 
Comments
or email your comment to: comments@i-programmer.info
|
|||
| Last Updated ( Wednesday, 05 April 2017 ) |