| DeepMind's Differentiable Neural Network Thinks Deeply |
| Written by Mike James | |||
| Thursday, 13 October 2016 | |||
|
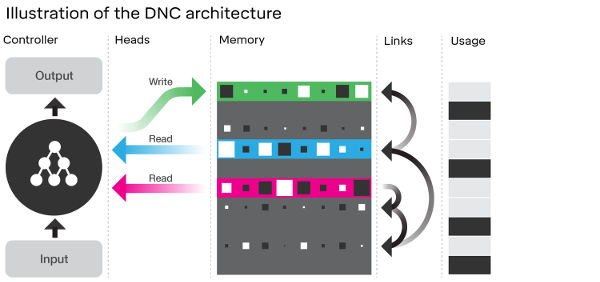
Neural networks are great at reacting to complex data, but not so good at the sort of slower thinking it takes to solve a problem like getting from A to B using a subway or unscrambling a sliding block puzzle. Now DeepMind seems to have discovered how to make neural networks think slow and deep. Two years ago DeepMind released information on its neural Turing machine - a clever idea that coupled a neural network with a memory in such a way that the resulting machine could still learn using the same approach a simple neural network. The key to the way a neural network learns is differentiability. In early attempts at building neural networks the neurons were either on or off and this all-or-nothing approach made it impossible to use optimization methods to improve their performance. The breakthrough was to use a more gentle transition from off to on that had a derivative - in the sense of calculus. Being able to take the network's derivative means that it is possible to work out how the networks' weights need to be adjusted to move the entire network in a direction that improves its performance. This is the back propagation algorithm and, while it has been revolutionary in its effect on deep learning, it really is just a standard classical optimization algorithm. Adding a memory to a neural network gives you new possibilities, but standard memories are all-or-nothing storage devices. If you add one to a neural network it immediately no longer has a derivative function and you can't use back propagation to train it. The clever idea with the neural Turing machine was to make the memory a gradual affair. When the network wrote to a location it wasn't changed from a 0 to a 1 but increased a little according to a weight parameter. This instantly turns the entire machine into something that again has a derivative and hence can be trained using back propagation. Neural Turing machines were impressive, but beyond their initial impact not much has happened using them. Now we have a paper in Nature describing the Differentiable Neural Computer (DNC) which is like the neural Turing machine but with a more sophisticated memory. The same sort of gradual approach is used to writing to the memory, but now there are mechanisms that control where the memory is active. There are three different attention mechanisms. Content lookup is where the output of the network is compared to the content of each memory location and the result is used to guide the read/write heads to areas of memory with similar content. The second uses the order in which data was written and the third, used for writing, makes it more likely that a write will be to a relatively unused area of memory.
"The design of the attention mechanisms was motivated largely by computational considerations. Content lookup enables the formation of associative data structures; temporal links enable sequential retrieval of input sequences; and allocation provides the write head with unused locations. However, there are interesting parallels between the memory mechanisms of a DNC and the functional capabilities of the mammalian hippocampus." The most important thing about each of these attention mechanisms is that they are differentiable and hence the entire machine is still trainable by classical optimization methods. To see if the DNC was better at the sort of slower logic problems that it was intended to solve, the team tried three tasks. The first a language reasoning task: “John is in the playground. John picked up the football.” followed by the question “ Where is the football?” The DNC did better than the usual approach to this sort of sequence problem, i.e. a Long short term memory (LSTM), and better than a neural Turing machine . The second task was to learn routes through graphs. This is identical to the problem of learning how to make a journey from one station to another in a complex network of rail lines and the team used the map of the London Underground and a family tree. On the Underground task the DNC reached an average of 98.8% accuracy after a million training examples. The alternative standard approach using a LSTM neural network failed to get beyond the first level of its training with an error of 37% after two million examples. You can see how it worked on the family tree example in this video:
The third task was to solve a sliding blocks puzzle, this time the training was based on reinforcement learning. This sort of problem is often solved using planning approach and the paper notes: We observed that, at the time a goal was written, but many steps before execution was required, the first action could be decoded from memory. This indicates that the DNC had written its decision to memory before acting upon it; thus, remarkably, DNC learned to make a plan. Again the DNC worked better than a conventional recurrent neural network. The paper also notes that that in each case the nature of the data changed the memory access procedures used by the DNC.
The final paragraph is worth reading: Our experiments focused on relatively small-scale synthetic tasks, which have the advantage of being easy to generate and interpret. For such problems, memory matrices of up to 512 locations were sufficient. To tackle real-world data we will need to scale up to thousands or millions of locations, at which point the memory will be able to store more information than can be contained in the weights of the controller. Such systems should be able to continually acquire knowledge through exposure to large, naturalistic data sources, even without adapting network parameters. We aim to further develop DNCs to serve as representational engines for one-shot learning, scene understanding, language processing and cognitive mapping, capable of intuiting the variable structure and scale of the world within a single, generic model. The really disappointing thing is that the paper in Nature is behind a pay-wall and it will cost you from $4.99 to $32 to read. More InformationDifferentiable neural computers Hybrid computing using a neural network with dynamic external memory Related ArticlesNeural Turing Machines Learn Their Algorithms Synaptic - Advanced Neural Nets In JavaScript Google's Neural Networks See Even Better The Flaw Lurking In Every Deep Neural Net To be informed about new articles on I Programmer, sign up for our weekly newsletter, subscribe to the RSS feed and follow us on, Twitter, Facebook, Google+ or Linkedin.

Comments
or email your comment to: comments@i-programmer.info
|
|||
| Last Updated ( Thursday, 13 October 2016 ) |