| The Web - The Early Years |
| Written by Historian | ||||
Page 2 of 3
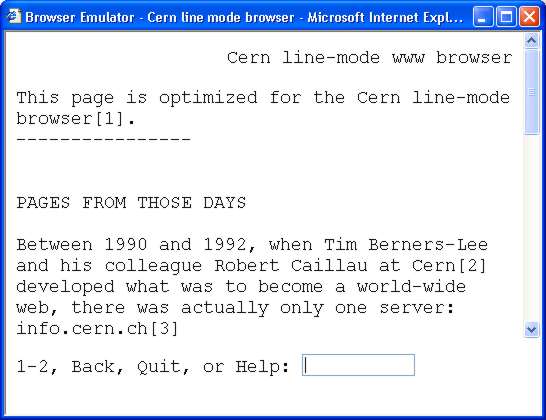
Webless!At the time people were using the Internet but there was no Web and this is difficult to understand from today's perspective. What did they do? Before the Web there were a range of ways to get at information. Of the protocols the only ones that are still in common use are newsgroups, email and FTP – File Transfer Protocol. When the Internet was first more generally available there were a lot of potential users who just didn't see the point. You could connect your computer to another computer irrespective of where it was in the world for next to free. At the time everyone was used to the fact that communications cost more the further the distance the data travelled. For example local telephone calls were cheap, long distance was more expensive and intercontinental calls needed a bank loan. I suppose the idea was that you paid for the length of cable you used. Packet switching changed this "charge by distance" model and it wasn't uncommon for early demos of the Internet to take you on a quick world tour of computers in far away places. This was scary - how much money were we spending? The answer was just as much as connecting to the local computer and more than often nothing at all. At first all the internet allowed you to do was to connect to a remote computer as if you were a terminal. We still use the Telnet protocol today but in those days it was more or less all you had. Once you connected to a remote computer you could browse its filing systems and list the contents of files. It was all very boring - unless the computer had some data you really needed. Another key fact to keep in mind is that everything on the Internet at that particular time was text based. Everything was done with simple console based programs and everything was a matter of typing. You even had to type in reference numbers to follow links.
The original browser – you had to type in the numbers to follow the links! You can try other old browsers out at www.dejavu.org.
Slowly additional services started to develop that became possible because of the Internet and the opportunities it offered for long distance communication and sharing data. We had email, FTP and a system called Gopher. This was invented at the University of Minnesota and for a while it looked as if could fill the niche that the Web does. It was a way of finding documents that consisted of a set of nested menus. You connected to a computer and it presented you with a top level menu and you slowly worked your way down the menus until you reached the document you were interested in. You then usually downloaded it to view it later. You could also perform searches on the menu hierarchy although not on the the documents themselves. It was a bit like using a remote file system. If you think that Gopher is primitive - at the time everyone thought it was great and laughed a lot about its name - Go For... get it?
gopher n. 1. Any of various short tailed, burrowing mammals of the family Geomyidae, of North America. 2. (Amer. colloq.) Native or inhabitant of Minnesota: the Gopher State. 3. (Amer. colloq.) One who runs errands, does odd-jobs, fetches or delivers documents for office staff. 4. (computer tech.) software following a simple protocol for burrowing through a TCP/IP internet. The start of Request for Comments: 1436 describing Gopher Eventually Gopher was killed off by the Web. Berners-Lee recounts a story about the University of Minnesota not being willing to drop the possibility that it might charge a licence fee in the future frightening off server implementer. However the fact that Cern placed the Web into the public domain was just one of its advantages. It was a more sophisticated system and it slowly grew in capabilities to become what we have today. The early Web however was text only just like Gopher and this too might come as a surprise. Berners-Lee thought that the Web should be about serious things and images shouldn’t be part of every page. The Web was all about text documents. Even so the Web was so attractive an idea that even without pictures it took off.
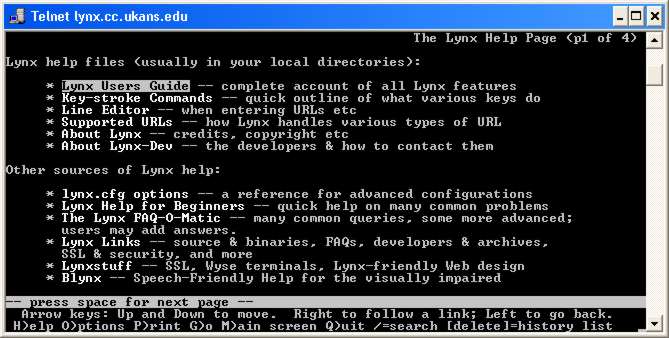
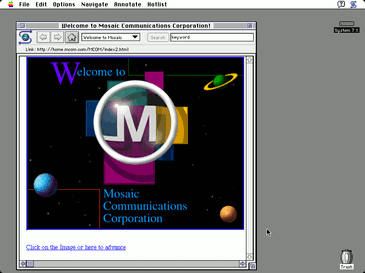
There are people who still find Lynx, an early text mode browser so much better than any of the modern browsers In 1992 the first text only browser was available by FTP download. At the start of 1993 the Web accounted for only 0.1% of the traffic on the Internet; by the end of the year this had risen to 1%. And again from a modern perspective you really have to ask what was the other 99% of the Internet being used for? At the end of 1993 there were 200 Web servers and six months later there were 1500. The Web just grew and grew and was rapidly becoming the only way to find and make information available. NetscapeThe next part of the Web story is less well known. In 1992 Marc Andreessen was a student at the University of Illinois at Urbana–Champaign and he decided to implement a new browser - Mosaic. This one was going to be available on a range of platforms – Unix, Windows and the Mac. By the end of 1993 over a million people were using it and it seemed like a good idea to go commercial. He teamed up with the ex-boss of Silicon Graphics, Jim Clarke and hired all but one of the original team from the university. The university wouldn’t release the browser to the new company, but they carried on regardless. The university didn’t just accept the position however and sued, claiming that Mosaic Netscape, the company, had stolen the name Mosaic and the browser code. Mosaic Netscape settled at a cost of $3 million and changed its name to Netscape and the browser to Navigator.
Marc Andreessen
The Netscape team had to write the browser again from scratch. The marketing plan was also very strange for the time. Instead of selling the product Netscape gave it away – unless you wanted to use it for commercial purposes when it charged you for it. In one year Netscape had 65 million users and it had Microsoft running scared.
It also had Tim Berners-Lee fairly irritated as well. Netscape started to innovate and extend HTML to include new tags that produced fancier formatting and embedded graphics. This made a typical Web page far more interesting too look at but Berners-Lee thought that it was making everything too trivial. The new image tag, which allowed images to be built into any Web page, was particularly worrying! He told Andreessen so on a number of occasions but it didn’t make any difference. Not only did the Web grow and grow so did its basic technologies. Navigator introduced the hyperlink – a clickable link to another Web page or to a location in the same page – and it was fully GUI with buttons and an exciting look. The Search ProblemThe Web continued to develop as fresh people saw new possibilities. The big problem was finding anything. In the early days there may have only been one Website but the number grew so rapidly that you just didn't know what was out there. The original idea was that the hyperlink would enable you to navigate your way to information relevant to any subject you were interested in. This was the hypothesis of the early pioneers - that the hyperlink was enough to organize all of human knowledge. Unfortunately they didn't count on the haphazard growth of the network of links. It was becoming difficult to find things. In 1994 Brian Pinkerton created a small application, a Web crawler, that searched the Web and created indexes of what was available. It was the first search engine and in 1995 it was sold to America Online and then in 1996 it was bought by Excite Inc. At about same time two students at Stanford University, David Filo and Jerry Yang, started a more ordered Web catalog called - "Yet Another Hierarchical Officious Oracle" or Yahoo! You may not believe this but much of the organization and construction of these early indexes was implemented by humans scanning the links that the crawlers found. It was really only when Google in the form of Larry Page and Sergey Brin invented page rank did fully automated Web search appear. Even today Google uses lots of humans to help in the process - something it doesn't discuss much. It is still the case that the big problem for the Web is finding things. |
||||
| Last Updated ( Monday, 08 May 2023 ) |