| Kinect SDK 1 - Skeletons |
| Written by Mike James | |||||
Page 3 of 4
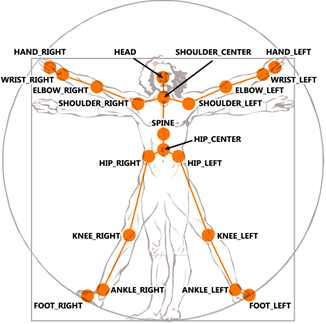
The SkeletonNext we need to investigate the data returned to the FrameReady. The first thing to say is that it isn't a skeleton. This is the most important thing to realize. What is returned is a collection of "joints". Roughly speaking a joint corresponds to a part of the human body. The online help has the following diagram to show you which parts of the body are tracked by the Kinect:
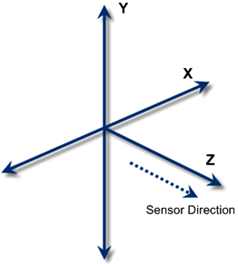
Each part of the body listed in the diagram returns a corresponding joint which gives its position and other useful data. The collection of Joints is returned as part of a Skeleton object which also has some other useful properties such as its position. The position of a Skeleton roughly corresponds to the center of the player (more accurately the centroid). Notice that no complex data regarding how the body parts are connected to form a skeleton is returned. If you want to draw a skeleton on the screen then it is up to you to join the appropriate body parts by lines. This is the sense in which the SkeletonFrame object does not represent a skeleton but you can see that it would be quite easy to write a routine that would connect appropriate parts of the body together with lines. How to do this is explained in the next chapter. Also notice that the data only contains the point location of each of the body parts. If you want to work out say the length of an arm you will have to do it by computing the distance from the shoulder to the elbow then to the wrist and finally to the hand. Getting The HeadAll we need to do is plot the position of the head and this just means finding the Joint corresponding to the player's head and plotting its position. Let's see how this is done. First we need to retrieve the SkeletonFrame from the event parameters: SkeletonFrame SFrame = e.OpenSkeletonFrame(); The SkeletonFrame has an array of Skeleton objects which we need to retrieve: Skeleton[] Skeletons= As always for a production program you need to create the Skeleton array or any resource just once and then reuse it for maximum performance. For simplicity we recreate the resouce as needed. The Skeletons array will contain a number of Skeleton objects in various states of tracking. So we need to process them all: foreach (Skeleton S in Skeletons) Each Skeleton object contains a collection of Joints as its Joints property but not all of the Skeletons will be actively tracked. Skeletons that are tracked have a valid collection of Joints. Skeletons that are not tracked only have a valid position. Before processing Skeleton data you need to discover if it is valid or not - the Kinect might not be able to track a user for one reason or another: if (S.TrackingState == If the data is tracked we can move on to process it. If you wanted to process the entire collection of body parts you would now write a foreach loop to scan though the collection and draw something for each one. In our case we simply want the Head Joint. This can be retrieved from the collection using its id: SkeletonPoint Sloc = We only need the Head's location, so we immediately use its Position property to return a SkeletonPoint object which contains x,y,z location as properties. At this point we have to consider what the skeleton location co-ordinate system is. Each body part is located using a standard reference frame:
The units used are meters and some times this is all you need to locate the player. However, we need to convert the 3D co-ordinates of the Joints into 2D co-ordinates that can be plotted in either a depth image or a video image. Chapter 5 goes into detail about how to convert the depth co-ordinates, x,y,z , into 2D video co-ordinates and the process of converting the skeleton data into 2D video co-ordinates is very similar. |